 "Plug'n and play analytics"
"Plug'n and play analytics"





Written by —

Written by —
It's time to check again what 2023 brought for us in terms of data warehouse and platform features. Whether you are considering investing in a new data platform and want to know which one offers the best value for your money, or you haven't had the time to check what features your favorite data platform added this year, this blog post is just for you. I've gone through all the product releases and release notes from several major vendors, picked the most important from them, and listed them here with a brief explanation of what those releases mean for each platform.
Personal note: The majority of this blog post was written in November 2023, and I checked the status of each release (both preview and GA) at the time of writing. I double-checked these statuses before publishing the blog. However, there may still be some errors, for which I apologize. I have included links to the features, allowing you to view the correct status by visiting the vendors' sites and their release notes.
Also: If you're on mobile, turn your mobile sideways for better reading experience.
This year has been a whirlwind for Generative AI, and its impact has also been noticeable in the realm of data warehousing. Major industry players have integrated, or are planning to integrate, LLM-based features into their data warehouses. Speaking of which, I must point out that the term 'data warehouse' is somewhat misleading nowadays. It's more appropriate to refer to these platforms as 'data platforms,' given that their offerings extend beyond mere storage and computation capabilities. However, I'll stick to 'data warehouse' in the title for the sake of consistency and to differentiate this conversation from customer data platforms (CDP).
In this article, we'll explore cloud-based data platforms that provide not only storage and computation services but also support for various programming languages (such as SQL, Python, Java, R, and more) and even come equipped with frameworks and integrated development environments (IDEs) for machine learning.
What data platforms are in the market then, and how do they differ? The list is rather long - Amazon Redshift, Google BigQuery, Microsoft Fabric, Snowflake, Databricks, Oracle Autonomous Data Warehouse, SAP Datawarehouse Cloud, Teradata Vantage, IBM Db2 Warehouse on Cloud and Cloudera Data Platform are all products on the market the offer capabilities for data warehousing, machine learning, and real-time analytics capabilities. To keep this article simple, I'll focus on the first five platforms, which are particularly influential in European markets and to be honest with the audience, are the platforms that our customers ask for when it comes to greenfield -projects.

"The big three"
This is to say that SAP and Oracle installations do exist, but they aren't popping up for new cloud-based projects, because AWS, Microsoft, and Google are the biggest cloud vendors in Europe, and new data platform projects tend to lean into using services from existing cloud platform (or leverage pure SaaS products).
If you want to check only specific data warehouses and their new product updates, I've created the following table of contents. Additionally, I've included a product comparison matrix where I have placed all the new releases in their respective categories.
- Product comparison matrix
- Azure / Microsoft Fabric
- Databricks
- Snowflake
- AWS / Amazon Redshift
- Google BiqQuery
- Conclusion
- Wishlist for 2024 - have you heard of vector databases, Motherduck and Knowledge Graphs?

Product comparison matrix
The following product comparison matrix highlights two aspects. Firstly, it illustrates how bustling 2023 has been with new releases, particularly services developed using Generative AI. Secondly, it sheds light on the overall state of cloud data warehousing. With a host of newly released features, Snowflake now aligns with other cloud vendors in Machine Learning capabilities. Additionally, with the release of Microsoft Fabric, you have the assurance that choosing any data platform will provide you with all the essential services needed to build your data platform. In the text that follows, I will delve into all these newly highlighted features.
This Product Comparison Matrix is not complete in the sense that it would contain all the services per feature per data platform. Instead the idea is to highlight whether the service has the capabilities or not.
| Feature | Snowflake | Databricks | Azure | AWS | |
| Serverless Compute "A service where compute is separated from storage" |
Virtual Warehouses |
SQL Serverless (new) |
SQL Analytics endpoint (new) |
BiqQuery |
Redshift Serverless |
| ML "Ability to pre-process, train, manage and deploy ML models" |
Container Services (new)/ Snowpark ML (new) |
Databricks Runtime / Runtime for ML |
Synapse Data Science (new) |
Vertex AI / Vertex AI API |
Amazon SageMaker / Amazon Bedrock (new) |
| Application runtime "Ability to host & run any kind of workload in data platform" |
Native Apps / Container Services (new) |
Container Services |
Azure Containers / AKS |
Containers |
Amazon ECS / EKS / Fargate |
| Generative AI "Ability to leverage LLM based services in a simpler manner" |
Cortex (new) |
Lakehouse AI |
Azure Open AI services |
Duet AI |
Amazon Q (new) |
| User Assistance "Ability to assist end users to generate SQL and code with natural language" |
Snowflake Copilot (new) |
Databricks Assistant (new) |
MS has 365 Copilot, but not yet for all Fabric Services |
Duet AI in BiqQuery (new) |
Amazon CodeWhisperer / Amazon Q (new) |
| User Search "Ability to search data assets with natural language" |
Universal Search (new) |
Lakehouse IQ / Semantic Search (new) |
N/A |
N/A |
N/A |
| Programmatic Access "Ability to use data platform services through code" |
SQL RestAPI / SnowSQL |
SQL Statement Execution API / CLI (new) |
Azure CLI |
BiqQuery REST API / bq command-line tool |
AWS CLI |
| OLTP functionalities "Ability to serve same data assets in columnar and row format while enforcing integrity" |
Hybrid Tables (private preview) |
N/A |
N/A |
N/A |
N/A |
| Notebook Experience "Ability to run code in Notebook manner" |
Snowflake Notebooks (new) |
Databricks Notebooks |
Synapse Data Engineering (new) |
Vertex AI Notebooks |
Amazon Sagemaker |
| Marketplace "Ability to buy, sell and search data products or add-ons to your data platform" |
YES |
YES (new) |
YES |
YES |
YES |
| ETL "Ability to ingest data and process it without the need of 3rd party services" |
Streams and Tasks / Container Services (new) |
Delta Live Tables / Containers |
Data Factory (newish) , Azure Functions |
Dataflow, Data Fusion, Cloud Run & Cloud Functions |
AWS Glue, Step Functions |
| Data Visualisation "Ability to visualize data for application & reporting usage" |
Streamlit |
Dashboards |
Power BI |
Looker |
Amazon Quicksight |
| Streaming "Ability to ingest & process real-time data" |
Snowpipe Streaming (new) |
Spark Structured Streaming |
Synapse Real-Time Analytics (new), Event Hub, Azure Stream Analytics |
Storage Write API (new), Data Flow, Pub/Sub |
Amazon Kinesis Data Streams |
We'll start with Microsoft, as I have been vocal in the past years that nothing is happening at Redmond and Synapse is getting sunset. This year Microsoft is making a strong comeback in the data platform market, attempting to re-enter the game with a product that is almost entirely 'new.' I've intentionally added quotation marks because Microsoft is heavily leaning on its previous products, albeit with their 'lakehouse' twist in the mix. For the existing Synapse Analytics users, Microsoft has released a blog worth reading, which explains the differences and upgrades that Fabric brings to existing Synapse customers.
I also recommend reading the following blog by Sam Debruyn, which goes into the details of each service to determine whether Fabric is just another rebranding. The blog also provides more insight into the underlying Polaris Engine, now utilized prominently in the Data Warehouse, which is entirely built upon this engine. This is a contrast to the Synapse Dedicated SQL Pools, which were based on the earlier Parallel Data Warehouse engine. The blog further provides insight into why creating an accurate product comparison matrix is quite challenging, as a single cloud vendor may offer a multitude of services for a particular use case, such as streaming input and processing.
Azure / Microsoft Fabric
 |
- Architecture: Lakehouse
- Highlighted feature from 2023: Fabric itself, which is now Generally Available, has created some long-waited hype around data platform capabilities in Azure
So, what is Microsoft Fabric? Essentially, Fabric comprises six core services. From a tooling perspective, we still have the Data Factory, but this new service differs from the previous Azure Data Factory (ADF). It combines Azure Data Factory with Power Query, offering extensive connectivity to various data sources, integration capabilities, and AI features for streamlined data pipelines and transformations.

"With Fabric I can finally understand these figures" |
Synapse Data Engineering, a newly introduced Spark-driven compute space, caters to those who prefer coding with notebooks. After the initial release in May Synapse Data Engineering has added several features such as lakehouse sharing, high concurrency mode, a notebook resource folder, and semantic data science, and in the future we will see support for Environments, Copilot, and CI/CD integration (all in the Public Preview now).
Another new service, Synapse Data Science, is specifically designed for data scientists to prepare and analyze data. It features tools like Data Wrangler, machine learning capabilities, and supports programming languages such as Python and R. After the initial release in May, Synapse Data Science has now support for Spark (Spark 3.4, Delta 2.4, Java 11, and Python 3.10) and Synapse ML 1.0. Future releases will have also natural language processing functionality powered by Azure OpenAI, enhancing code generation efficiency. In a similar manner to Data Engineering, Synapse Data Science includes Copilot experience in Notebooks to boost developer productivity.
|
|
Synapse Real-Time Analytics, another new component, focuses on delivering real-time data insights, such as running analytical queries directly on raw data. It offers capabilities for instant report generation, integration with Microsoft OneLake, and support for complex data transformations. The difference between Data Engineering and Real-Time Analytics can be better understood through Microsoft's explanation, which highlights Real-Time Analytics as more suited for low latency needs "You can stream large volumes of data into your KQL database through Eventstream with a latency of a few seconds, then use a KQL queryset to analyze your campaign's performance and visualize your findings in a shareable Power BI report."
Finally, Synapse Data Warehouse, Microsoft's next-gen data warehouse, is now SaaS, working on a serverless compute infrastructure. This eliminates the need for dedicated clusters and allows for efficient resource provisioning and utilization. It also features the separation of storage and compute, enabling independent scaling and cost management for each. Similar to Databricks, the new Synapse Data Warehouse supports open data standards, storing data in Delta-Parquet format within Microsoft OneLake. This ensures interoperability across Fabric workloads and the Spark ecosystem without necessitating data movement.
After the Public Preview phase in May, Synapse Data Warehouse has added features such as automatic statistics, zero-copy table cloning, data warehouse deployment pipelines, and REST API and SQLPackages for warehouse control. In the future we will see also GIT integration, the ability to transform and load data into the Warehouse using Power Query experience with Dataflows Gen2, and the ability to Mirror database to be used from any Fabric service. This means that "with Mirroring, data across any database can be cross joined as well enabling querying across any database, warehouse or lakehouse whether that be data in Azure Cosmos DB, Azure SQL DB, Snowflake, MongoDB etc."
|
|
All these tools integrate with or utilize data from OneLake, Microsoft's unified, multi-cloud data lake solution. OneLake is likened to 'OneDrive for data', featuring unified management, data mesh, domains, openness, and ease of access via a dedicated file explorer app for Windows.
With the introduction of Fabric, many companies might be thinking about what's going to happen to Synapse. As per Microsoft, there are no plans to retire Synapse Analytics and you can keep using your existing Synapse Analytics environment and enhance it bit by bit with Fabric -capabilities.
Databricks
 |
- Architecture: Lakehouse
- Highlighted feature from 2023: SQL Serverless went GA, thus tightening the cap between Snowflake by creating similar functionality as Snowflake's Virtual Warehouse.
Jumping into the GenAI train
Generative AI is now everywhere and all the vendors are adding functionalities around GenAI. As GenAI works well with text-based (like SQL) input, the most obvious additions are assistants and data tagging and or text generation. So with this information, it's you are not surprised by the features added to Databricks.
 "Own your models - get better results" "Own your models - get better results" |
Before delving into the actual features, it's notable that Databricks, like many other vendors, has joined the Generative AI trend. They even released their own LLM model, Dolly, as a way to enable businesses to have more control over the model and to use it for targeted or specific use cases. This is where the competition, such as ChatGPT, has limitations on commercial usage. LLMs were also a trend on Databrick's latest announcement, the set of RAG tools meant help users to create LLM apps. These services include for example a vector search (more about Vectors in the final chapter of this blog), quality monitoring to observe the performance of RAG apps, and fully managed foundation models that provide pay-per-toke base LLMs.
Databricks Assistant (Public Preview) is one of the many AI-based features added to Databricks. Databricks Assistant is an AI-based coding assistant set to improve efficiency in writing and optimizing code and queries within Databricks. Think of this like having a smart helper while you're writing in a computer language. It suggests how to complete your code, helping you write it faster and better.
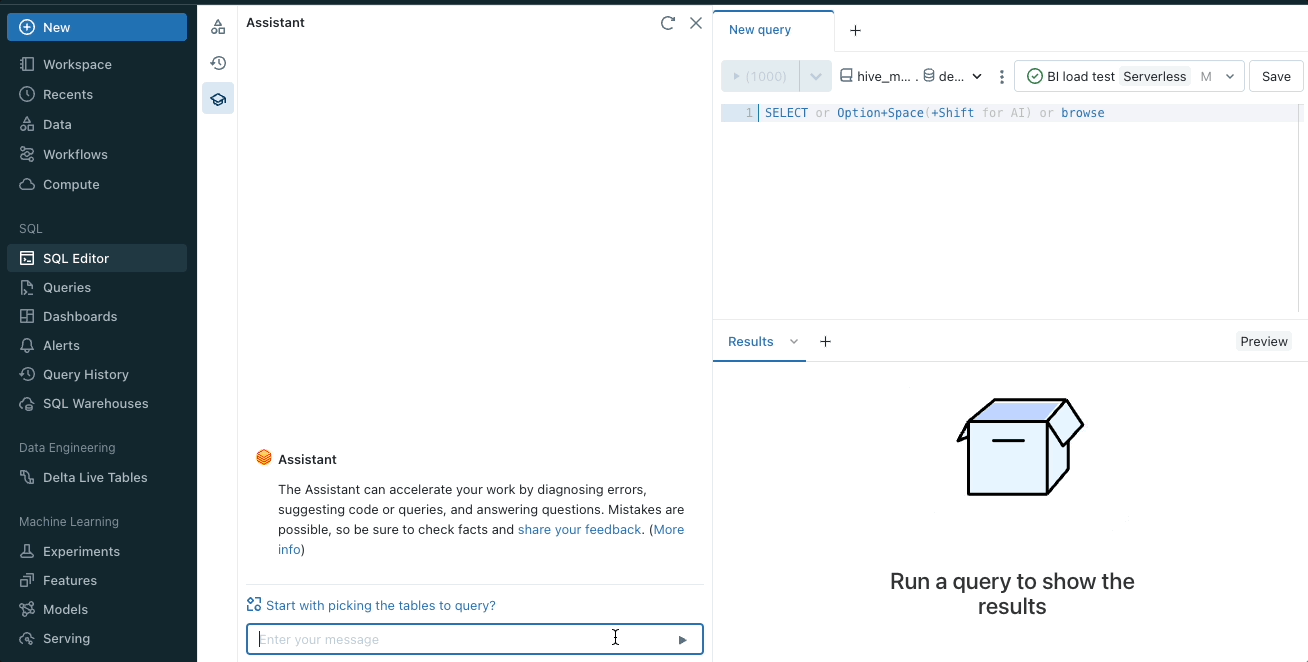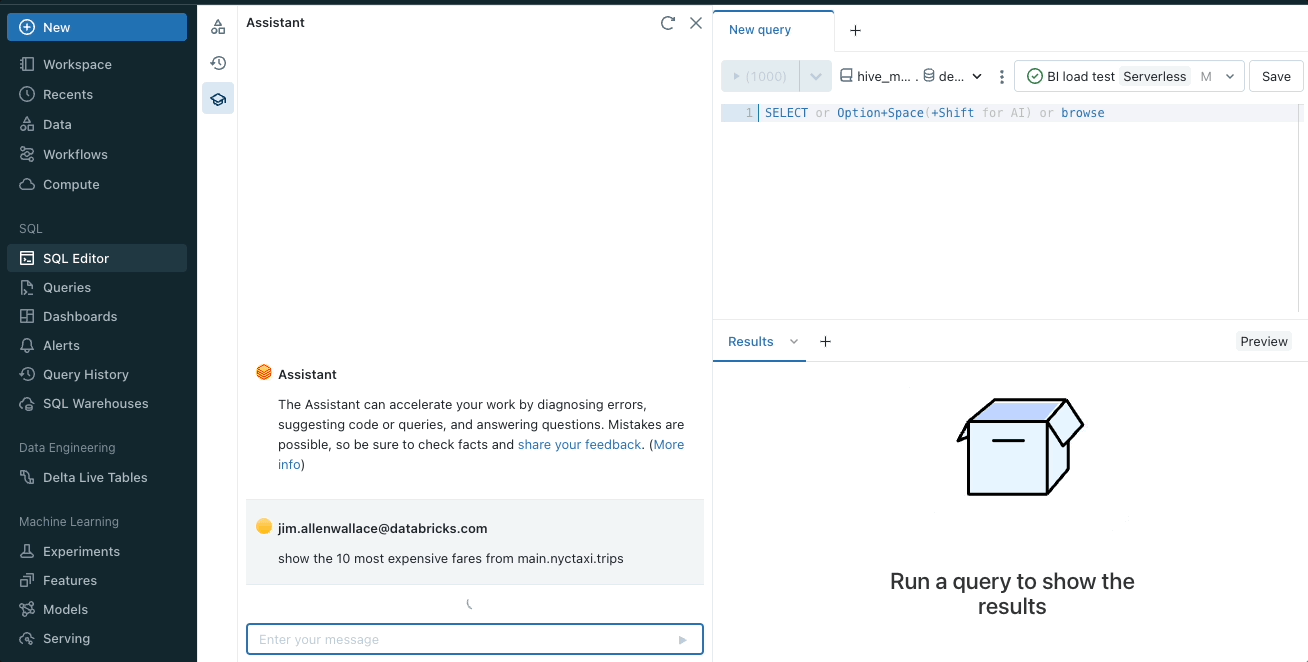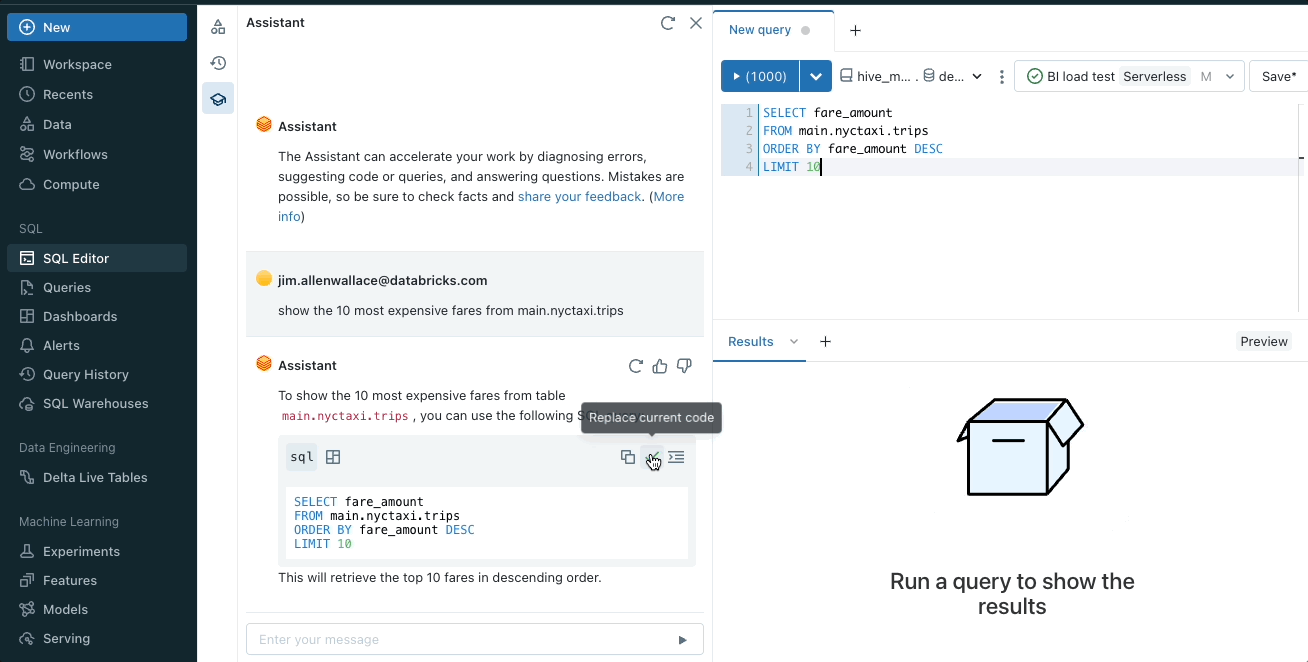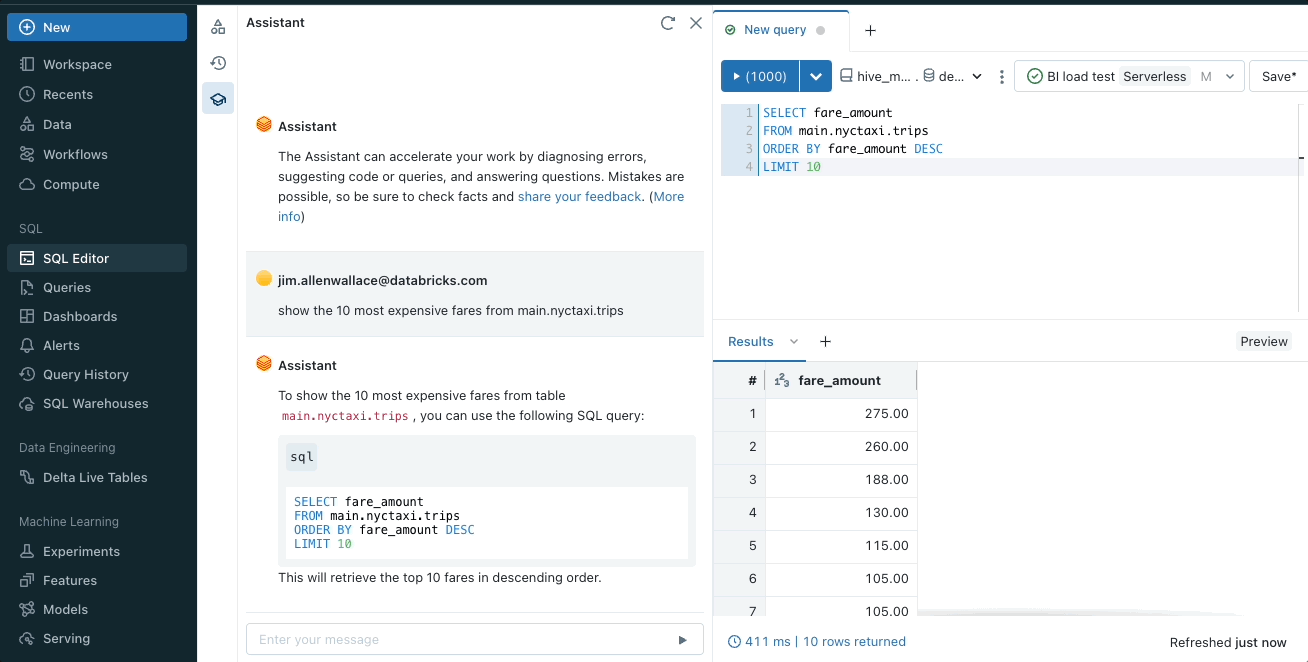
"Databricks Assistant in use - Gif taken from Databricks blog" |
AI is leveraged on Unity Catalog as well, as AI-Generated Documentation in Databricks Unity Catalog (Public Preview) leverages generative AI to automate the creation of data documentation. This enhances data discovery and fosters clearer understanding and collaboration in data analysis, akin to AI creating an instruction manual for your data that helps people find and understand the data they need. On the same documentation topic, AI-generated Table Comments (Public Preview) is an innovative feature in Databricks that uses artificial intelligence to automatically generate descriptive comments for tables and columns. This improves data understandability and documentation, much like sticky notes for your data tables, created by AI to explain what's in the tables, making it easier for everyone to understand what the data is about.
Other important AI-related features from Databricks were
- Llama 2 Foundation Models in Databricks Lakehouse AI which offers access to Meta AI's chat models for fine-tuning, and promoting advanced AI conversations and analytics within Databricks.
- LakehouseIQ (Announcement), which is a knowledge engine that adapts to business-specific data and terminology, improving natural language data interactions and analytics.
- LangChain (Availability in Databricks Runtime 13.1 ML and above) which provides tools for integrating large language models in applications, enhancing machine learning workflows within Databricks.
- Semantic Search (Public Preview) which enhances data discovery with natural language search capabilities for Unity Catalog tables.
|
"Lakehouse IQ under construction." |
Finally, flexibility in SQL queries
In terms of the basic functionalities, Databricks released SQL Serverless as General Availability. SQL Serverless provides a serverless SQL query execution environment, offering instant compute resources with cost optimization, and minimizing management overhead. SQL functionalities do not end there as Databricks SQL Statement Execution API went also into GA. As you might guess, it's a REST API for executing SQL statements, enabling programmatic data manipulation and interaction with the Databricks SQL warehouse. On the newer releases, Databricks notebooks can be executed in SQL warehouses as Databricks Notebooks on SQL Warehouses went into Public Preview. Delta Lake also got Prediction Optimization for Delta Lake (Public Preview) which automates the maintenance of Delta tables, optimizing for performance and reducing manual overhead. Together with updates like liquid clustering and predictive I/O, Databricks has put in a lot of work to make the SQL experience better out of the box.

"I am predicting massive amounts of data coming into data lakes and people asking to do AI from them" |
For developers, Databricks added Databricks Extension for Visual Studio Code (General Availability) which enhances developer experience by allowing them to interact with Databricks directly from Visual Studio Code, offering features like interactive debugging and notebook execution and Databricks CLI (Public Preview) which helps automation and interaction with the Databricks platform through the terminal.
Outside of these new features, Databricks released Lakehouse Federation (Public Preview) which enables querying across multiple external data sources without data migration, improving speed and flexibility for analytics and ETL processes. Lakehouse Monitoring (Public Preview) is a new feature that integrates monitoring of data and model quality, providing metrics and alerts to maintain high data standards. Databricks Marketplace (General Availability) facilitates the discovery and integration of data products and notebooks, expanding the ecosystem for AI and analytics workflows.

Snowflake
 |
- Architecture: Hybrid (Data Lake + Data Warehouse)
- Highlighted feature from 2023: Container Services (in public preview soon at AWS), Snowflake's own "Kubernetes -cluster" for any kind of workload thus narrowing the gap in ML/AI -capabilities between the competition.
Catching the competition on ML
The previously known fact was that Snowflake lagged behind the competition in ML capabilities, although Snowflake had introduced Snowpark and had support for 'non-SQL' workloads. This changed in 2023 when Snowflake introduced several new features that enable users to run ML workloads and use Generative AI features on the same Snowflake account.
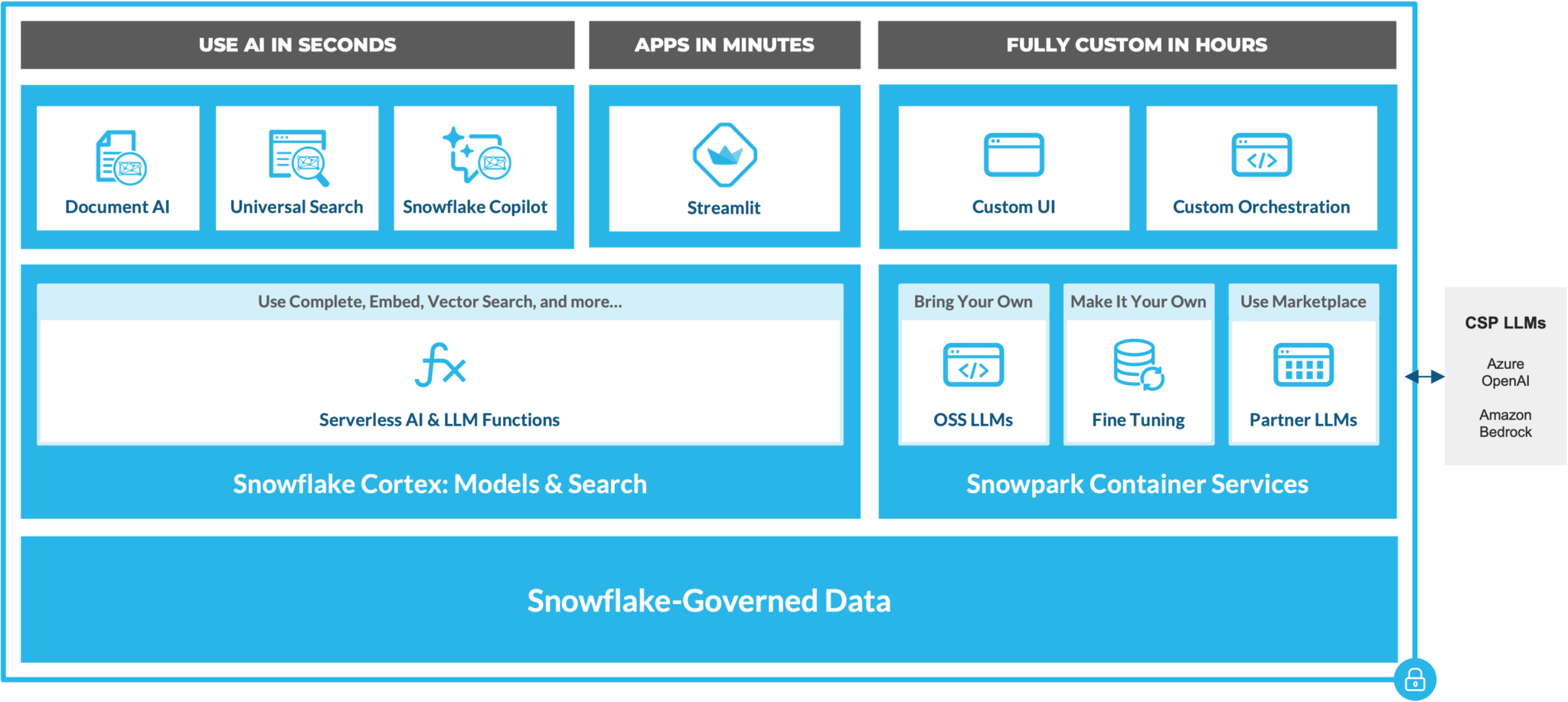
"Overview of GenAI and LLM capabilities in Snowflake as pictured in Snowflake blog" |
Starting with the Generative AI features, Snowflake released Cortex (in private preview), a new fully managed service that allows users of Snowflake to start using ML and LLM models tuned for specific tasks with serverless functions. In the beginning, these ML and LLM functions include, for example, ML-powered functions, like Forecasting, Anomaly Detection, Classification, and Contribution Explorer. The LLM -based functions are
- Answer Extraction (in private preview): Retrieve key details from your unstructured data.
- Sentiment Detection (in private preview): Detect the sentiment of text across your table.
- Text Summarization (in private preview): Summarize long documents
- Translation (in private preview): Translate text
On top of these Snowflake also introduced the following models.
- Complete (in private preview): For given a prompt, the function returns a text completion response
- Text2SQL (in private preview soon): SQL is generated from natural language
|
"Copilot in use" |
Cortex is also behind the new LLM-based features of Snowflake Copilot (in private preview, similar to DuetAI, Microsoft Copilot, and Databricks Assistant), which helps users of Snowflake to generate and refine SQL with natural language, Universal Search (in private preview) which helps find database objects from your account (at initial release it's limited to tables, views, databases, schemas, Marketplace data products, and Snowflake documentation articles). Finally, we got Document AI, which uses pre-trained model process documents (PDF, word, txt, screenshots) and together with a UI, allows users of Snowflake to get answers to their questions (you can think of this as OCR, but the capability of understanding the content).
As stated above, together with Cortex, users of Snowflake can in the future run any code inside Snowflake using Container Services. Container Services is a Kubernetes -like implementation where you have the image registry inside Snowflake and as compute you use the familiar virtual warehouses. With Container Services, we will also get GPU -compute, as Snowflake has partnered with NVIDIA to bring their NVIDIA AI Enterprise -platform, NeMo, and NVIDIA GPUs to Snowflake. With Container Services, you can now run any kind of workload, even host your own ETL -software within Snowflake or for example your own Hex -installation. I'm eager to see when we witness the first dbt Core inside Container Services installation.
For more information about Container Services and its insides like, image registries, compute pools, and such, I recommend reading the following tech primer by Caleb Baechtold.
Final upcoming feature for the Snowflake ML -capabilities is Snowpark ML (in preview), which is a set Python tools, including SDKs and underlying infrastructure, for building and deploying machine learning models within Snowflake. The preview includes preprocessing and modeling classes such as scikit-learn, xgboost, and lightgbm. In the future, we can expect also data provisioning for Pytorch and Tensorflow frameworks in their native data loader formats.
Updates to Snowflake Core features
I'll start with the most important of all for developers - Git Integration is finally (in private preview) coming to Snowflake as demonstrated by Jeff Hollan in the video below. Now you can push changes to Git and with the new API and GIT REPOSITORY -commands, you can define the Git -repository within Snowflake.
Snowflake / Jeff Hollan - Snowflake Git Integration with Snowpark
Query Acceleration Service is a feature that is a bit unknown even for existing Snowflake -customers, but it's now in GA. Under the hood, QAS accelerates automatically parts of your query to compute resources that are currently available. Think of it as a feature, where you scaled and optimized everything accordingly, but still, you faced queries that consume more resources than expected. QAS helps you with those use cases. QAS works automatically out of the box, but you'll need an Enterprise account or higher.
Other significant updates were the General Availability of Snowpark-optimized Warehouses, which have more memory to support ML-use cases, Network Rules (in Preview) which help Snowflake admins to define better rules based on ingress and egress traffic (if you have previously defined any network rules on Snowflake, you'll know how basic the features have been). tl;dr; you can finally use Azure LinkIDs or AWS VPCE IDs instead of fixed IP segments.
|
"Data Engineer working with JSONs" |
You know JSONs? JSONs are excellent for everything, but horrible for data ingestion without data contracts. I mean if you have worked with any data source providing JSONs, you know what I mean when I talk about schema drift and schema versioning. You might assume that schema versioning is de-facto and happening everywhere. You're wrong. If you have data engineers working on JSON-based data sources, I will guarantee that the lack of schema versioning is their biggest pain point on integrations. Snowflake has now introduced a feature that won't remove the pain, but help you with integrations. Table Schema evolution and Schema detection (both GA) are available for Apache Avro, Apache Parquet, CSV, JSON, and ORC files and are meant to help you detect and add new columns on new files as they appear, on the COPY INTO -statement. The next step is just to make sure that you're automation tool supports this feature.
Finally, we got a small general availability update, but a feature that is helpful to a lot of data engineers. GROUP BY ALL. If you have ever written SQL, you'll understand. No longer do you need to specify all the columns because you can use use GROUP BY ALL -keyword and streamline your SQL queries.
Something for the developers
Snowflake is getting Notebooks, "a Jupyter-like" -experience to run Python -code inside Snowsight. Notebook experience has been previously possible, for example with Hex, but after Snowday 2023 -accouncement, we are finally getting them inside Snowsight. Before Notebooks, Python worksheets went into Public Preview -state and are available for all accounts.
Notebook experience and Python worksheets will be helpful in the future in application development as Native Applications Framework went into Preview -state in AWS -accounts. You can develop and publish your Streamlit -application inside Snowflake -account for users inside your own organization (or outside) to be used (bear in mind that preview has limitations for Streamlit compared to native Streamlit running in Streamlit Cloud). Together with Native Applications Framework -preview, we got a Native SDK for Connectors (also in preview), which is a set of application templates and quickstarts that show how to build a Snowflake Native App that ingests data from an external data source into Snowflake.
Monitoring improvements
For data engineers responsible for data pipelines, Snowflake released Alerts, which act like your normal data quality checks where you define SQL -rules like "IF( EXISTS(SELECT gauge_value FROM gauge WHERE gauge_value>200)) THEN INSERT INTO gauge_value_exceeded_history VALUES (current_timestamp());". Difference between normal data quality checks, which are part of your existing ETL pipeline, Alerts have more options, like the possibility of sending a notification or performing an action.

"This is fine - Now I know if my platform is burning" |
Alerts also have their schedules (intervals) and work in the background regardless of your own ETL -pipelines. In the same topic of monitoring, Snowflake released Budgets into Public Preview. Budgets is a similar feature as existing Resource Monitoring but works on a more granular level allowing Snowflake users to monitor credit usage for a custom group of objects. Monitoring improvements didn’t end there, as Snowflake introduced Horizon, a new built-in governance solution offering unified compliance, security, privacy, interoperability, and access capabilities. Horizon is not just a marketing gimmick; it offers a Data Quality Monitoring UI (in private Preview), a Data Lineage UI (in private preview), and a Trust Center (in private preview soon).
The enabler stuff
These features by themselves sound only technical features, but when combined with data pipelines and/or applications, do make a significant difference. Let's start with Snowpipe Streaming (Snowflake documents do not state whether it's already GA), which offers an API that enables you to write data directly into Snowflake tables, without using COPY INTO -statements. When you think that in a broader concept, you realize that you now have the beginnings of creating better real-time pipelines. When you combine Snowpipe Streaming with Dynamic Tables (in preview) which offers a simpler way to define the end state for your data Snowflake handles the pipeline management.
Finally, we have a feature that will change how you can create data applications on top data platforms and data warehouses. Hybrid tables (in private preview) will offer OLTP-like features for data warehouses and in preview state are achieving double-digit millisecond latency and thousands of queries per second (QPS) throughput as per Snowflake documentation. To the common man, Hybrid tables are like your normal tables in any classical RDBMS and thus enforce primary keys and referential integrity constraints, and have secondary indexes for accelerated lookups. Normally you can't do these with MPP-architecture databases and when done properly will change the way you think about the capabilities of data platforms.
AWS / Amazon Redshift
 |
- Architecture: Hybrid (Data Lake + Data Warehouse)
- Highlighted feature from 2023: Amazon Q, a new Generative AI -based assistant that is going to be bolted onto several AWS services
Talking about AWS and Redshift is always a bit challenging because if we were to simply list all the features that Redshift gained during 2023, it might seem as though the platform's capabilities on AWS are lagging behind. Due to this, I'll include a few features related to data platform capabilities on AWS, but not specific to Redshift.
Core feature enhancements
Like Snowflake, Amazon Redshift now supports familiar MERGE and QUALIFY SQL clauses and under the hood got support for Dynamic Data Masking, which allows security administrators to create SQL-based masking policies, enabling format-preserving and irreversible masking of data values. Masking can be applied to specific columns or a list of columns in a table, with flexible options for displaying masked data, including complete hiding, partial replacement with wildcard characters, or custom masking using SQL Expressions, Python, or Lambda User Defined Functions.
Redshift joins the list of products supporting Apache Iceberg by enabling querying capabilities for Apache Iceberg tables. You might be wondering why this is significant. One reason is the increasing prominence of data lakes and the ongoing "format war" to become the de-facto standard for future data lakes. A transactional data lake stores both structured and unstructured data and supports transactional operations, ensuring data accuracy, consistency, and trackability over time. For this purpose, a format supporting ACID transactions is essential, and Iceberg excels with features such as SQL familiarity for building data lakes, data consistency, flexible schema evolution, data versioning, cross-platform support, and incremental processing for enhanced efficiency.
 |
Redshift joins the list of products supporting Apache Iceberg by enabling querying capabilities for Apache Iceberg tables. You might be wondering why this is significant. One reason is the increasing prominence of data lakes and the ongoing "format war" to become the de-facto standard for future data lakes. A transactional data lake stores both structured and unstructured data and supports transactional operations, ensuring data accuracy, consistency, and trackability over time. For this purpose, a format supporting ACID transactions is essential, and Iceberg excels with features such as SQL familiarity for building data lakes, data consistency, flexible schema evolution, data versioning, cross-platform support, and incremental processing for enhanced efficiency.
Another reason is that Apache Iceberg, an open-source data table format from the Apache Software Foundation, is a major competitor against Delta Lake. Therefore, these releases where products start to support Iceberg are critical in expanding Iceberg's usage, especially as it's designed for large datasets in data lakes and is renowned for its speed, efficiency, and reliability.
Redshift Serverless also got more flexibility when it introduced a lower base capacity configuration option for its Serverless service, now starting at 8 Redshift Processing Units (RPU) compared to the previous minimum of 32 RPU. Amazon Redshift Serverless is now more accessible for both production and test environments, especially when only a small amount of compute is needed and especially tied together with the introduction of MaxRPU, a new compute cost control feature for its Serverless service. MaxRPU allows users to set an upper compute threshold for each workgroup, controlling data warehouse costs by specifying the maximum compute level that Redshift Serverless can scale to at any given time. This complements the existing ability to limit overall spending through RPU-hour usage limits, which includes options for alerts and automatic query shutdown upon reaching the limit.

"Work faster - The end user has requested more Processing Units" |
Finally, the previously announced Amazon Aurora MySQL's zero-ETL integration with Amazon Redshift is now generally available, offering near real-time analytics and ML on transactional data. This integration eliminates the need for complex ETL pipelines, as data from Aurora is instantly available in Redshift. It supports various Aurora and Redshift versions, including Serverless v2 and RA3 instances.
One of the database related highlights of recent AWS ReInvent was the the introduction of Amazon Aurora Limitless Database. This new capability in Aurora is a game-changer, supporting automated horizontal scaling to handle millions of write transactions per second and manage petabytes of data in a single database.
Meanwhile, Amazon DocumentDB introduced vector search, now generally available. This feature allows users to store, index, and search millions of vectors with millisecond response times, enhancing the efficiency of operations within the document database. It's particularly beneficial for applications requiring high-speed searches over large vector datasets, like for example those dealing with complex data structures, like a recommendation engine in an e-commerce platform. This feature enables lightning-fast searches across large datasets, making it effortless to find relevant products based on customer preferences.
AWS Lambda functions have also seen a major upgrade with significantly faster scaling capabilities. Now, each synchronously invoked Lambda function can scale by 1,000 concurrent executions every 10 seconds, up to the account's concurrency limit. This enhancement is crucial for handling high-volume requests more efficiently, providing a more responsive and reliable serverless experience. In the storage domain, Amazon S3 introduced the new Amazon S3 Express One Zone high performance storage class. This class is designed to deliver up to 10x better performance than the S3 Standard storage class, making it ideal for frequently accessed data and demanding applications.
|
Lastly, Amazon introduced their on Generative AI based assistant, called Amazon Q. Amazon Q enables users to leverage conversations, solve problems, generate content, and gain insights by connecting to a company’s information repositories, code, data, and enterprise systems. Amazon Q can be used together with Quicksight and with Redshift (in Query Editor) to auto-generate SQL.
Google / BiqQuery
 |
- Architecture: Hybrid (Data Lake + Data Warehouse)
- Highlighted feature from 2023: Editions, editions, editions. Goodbye fixed-rate plans, say hello to the pay-per-use model
As highlighted, the biggest change in BigQuery came with the introduction of Editions, a new pricing model that replaces fixed-rate plans with a pay-per-use system measured in slot/hours, a model similar to that used by Snowflake. Editions offer different service levels to meet the diverse needs of users. In Google BigQuery, 'Editions' refer to a set of structured service and pricing plans, allowing users to select a service level (Standard, Enterprise, or Enterprise Plus) that best fits their data analysis needs and budget. Costs are based on actual resource consumption (slot/hours used) rather than pre-purchased capacity. Integral to Editions is the autoscaling model, where reservations with slots autoscaling are only available through Editions. Autoscaling in BigQuery is a model where you can scale the allocated capacity to accommodate your workload demands using slots.

|
"By choosing your edition, you influence your bills under the new pricing model."
Several additions to core functionalities
A familiar feature from fellow data warehouses is Query queues, which allows BigQuery to automatically manage query concurrency, queuing excess queries until resources are available. Together with the Query execution graph, users can now get better insights into query performance, helping to diagnose issues. Continuing with familiar features, BigQuery supports Primary and foreign key table constraints which can be used to enhance data integrity by enforcing relationships between tables. BigQuery also got Table clones which enable you to duplicate tables for various purposes without copying the data and using that same technology there is now Fail-safe period information which provides an additional seven days of data storage after the time travel window for emergency recovery. Finally we got BigQuery supports now Apache Iceberg tables (together with BigLake Metastore which enable access and management of Iceberg table metadata from multiple sources) and Change data capture (CDC) in BigQuery which allows real-time processing of changes to existing data using the Storage Write API.
The AI stuff
|
"ML.GENERATE_TEXT" |
Just as we have Copilot within the Microsoft ecosystem, Google has introduced Duet AI, and as of 2023, it has become possible to use Duet AI in BigQuery. Duet AI in BigQuery can help you complete, generate, and explain SQL queries. This feature is currently in preview. For the common 'data engineer', the following AI features are understandable and don't require much groundwork to get started with, and thus might come in handy in the future. These include the ability to process documents from object tables with the ML.PROCESS_DOCUMENT function, transcribe audio files from object tables with the ML.TRANSCRIBE function, and, as an LLM-based feature, the possibility to perform generative natural language tasks on text stored in BigQuery tables using ML.GENERATE_TEXT function. All these have become possible because Object tables are now generally available (GA). Object tables are read-only tables containing metadata for unstructured data stored in Cloud Storage."
Alongside BigQuery added ML integration between BiqQuery and Vertex AI Model Registry, which allows BigQuery ML models to be registered and monitored using Vertex AI, supporting the deployment of models and comparison of evaluation metrics.
BigQuery ML also got a hefty amount of Generative AI features, such as the possibility to create a remote model based on the Vertex AI large language model (LLM) text-bison (there are a multitude of other models, but generally offered models are bison and gecko), additions to time series forecasting, like ML.HOLIDAY_INFO function which returns the list of holidays being modeled by an ARIMA_PLUS or ARIMA_PLUS_XREG time series forecasting model.
DataFrames are now hot

"bigframes.pandas" |
BiqQuery is also jumping into DataFrames and Notebooks with the release of BigQuery Studio which is now in preview. Within BigQuery Studio, you'll get Python notebooks which are powered by familiar Colab Enterprise (at least I have used Colab several times due to their free tier compute) and within Python notebooks, you now can use BigQuery DataFrames (in preview - similar feature Snowflake Snowpark DataFrame). In the preview, you'll get the possibility to use bigframes.pandas (a DataFrame on top of BiqQuery) and bigframes.ml (a Python API for BiqQuery ML). The asset management and version history for notebooks are handled by Dataform.
Conclusion
After reviewing all the features released in 2023, it seems that now all data platforms offer the necessary features to support any type of workload. However, it’s essential to recognize that no technology, whether Snowflake or Databricks, can resolve issues if the underlying data model is flawed.
Both Generative AI and AI require proper data and data models to function effectively. To stay ahead in the game, you need to build a data platform that provides accurate data right from the start, which means choosing and implementing the right data modeling approach from day one.
When it comes to data modeling, my advice is to select your data model first and then choose a platform that supports this model and offers the necessary automation tools. And I'm serious about choosing your data model; don’t try to reinvent the wheel or mix and match the best parts of different models. By opting for industry-standard models like Data Vault, you ensure access to suitable automation tools, expertise in the field, and a wealth of reference projects.
|
"Both Generative AI and AI require proper data and data models to function effectively." |
Why insist on selecting the data model before the data platform? It forces you to think what problem you're actually trying to solve (it might be actually an process problem, not a data problem) and also ensure that whoever is implementing the data platform is competent and not just a tech enthusiast implementing the latest technical platform for the fun of it.
Here’s a tip to spot the over-enthusiasts: if they propose combining Databricks, Microsoft Fabric (or any Lakehouse solution) with Data Vault, be wary. Data Vault is known for its numerous joins, which Lakehouse solutions can’t handle efficiently. A better option would be a Databricks and dbt combo with more classical models like Inmon and Kimball. Also, be sure to use Unity Catalog and SQL Serverless from the outset.
Regardless of the data platform you choose, it’s crucial to use an industry-standard automation tool like dbt. Utilizing such tools helps you avoid dependencies on specific people or companies.
Wishlist for 2024 - have you heard of vector databases, MOTHERDUCK, OR KNOWLEDGE GRAPHS?
Personally, I believe that the integration of AI-driven tools is not just a trend but a significant leap towards more intelligent and intuitive data platforms. With that said, I wish to see the integration of the Copilot / DuetAI experience evolve. This will help 'citizen data engineers' start using SQL and get their answers without the need for static reports. On the trend of AI, I also expected to see the integration of vector database features into existing data platforms. Oracle has already announced its plan to integrate a vector database into Oracle Database 23c, Amazon added vector search into DocumentDB and Databricks informed about the Public Preview of their Vector Search, so I assume that the competition isn't far behind.
|
"Repeat after me, kids - Vectors are easy" |
You might ask, 'What the heck is a vector database, and why is it important?' A vector database is a specialized type of database designed to store and manage data in the form of multi-dimensional numeric vectors. This is a stark contrast to traditional databases that organize data in rows and columns. In a vector database, data, whether it be images, text, or audio, is encoded into a vector format. This format essentially serves as a numeric digital signature that captures the essence of the data. The significance of vector databases lies in their ability to efficiently handle and retrieve these vector representations, which is crucial for powering generative AI models. Models like GPT-3 for text or DALL-E for images rely on understanding and synthesizing complex patterns from massive datasets. The vectorized format of data in vector databases enables these AI models to process and generate human-like creative outputs efficiently.
Why is it important to start looking into vector databases? By now, you might have noticed that Generative AI comes with a price, and the more specific demands you have, the better it is to self-host the entire solution. For this, you'll end up setting up a vector database. Once you reach that solution, you'll want all the features that a 'normal' database in your stack has, for example, support. By that time, you'll also wish, like me, that your existing data platform would support vectors.
Aside from vectors, I'll set aside the discussion of Knowledge Graph -databases like RelationalAI, which has added former Snowflake CEO, Bob Muglia to the board. For RelationalAI, check the following video which explains the use cases and how you can run RelationalAI inside Snowflake Container -services. I'll instead focus on introducing Motherduck, because it has features that might end up into the major players in the future.
You can't talk about Motherduck without first talking about DuckDB and what DuckDB is. DuckDB represents a significant innovation in the realm of database management systems, standing out with its in-process SQL OLAP database design. This unique setup allows DuckDB to run within the same process as the application it's serving, rather than functioning as a separate server. This integration simplifies the overall architecture and eliminates the need for network communication or separate server processes, thereby streamlining data processing. DuckDB is particularly adept at handling complex analytical queries and managing large datasets, a capability that stems from its vectorized query execution. This method processes data in large batches, significantly speeding up query response times and making DuckDB an excellent choice for data-intensive applications.

"DuckDB admin at work" |
This means that DuckDB excels in scenarios where high-performance data analysis and handling of large datasets are essential. Its design makes it particularly suitable for applications that involve heavy data processing and complex analytical tasks. The database's embeddable nature also makes it ideal for embedded analytics, where direct integration within an application is necessary. This capability ensures seamless data analysis and management, providing a robust solution for a wide range of applications.
So, what exactly is Motherduck? It's the company behind DuckDB, and they have now developed a serverless cloud analytics platform based on DuckDB, also named Motherduck. Essentially, it's DuckDB running in the cloud, but as a serverless and scalable version. I'm now eagerly awaiting to see whether the features of Motherduck will be integrated into an existing data platform, or if Motherduck will grow to become a major contender in the field of analytics.
For other future features, I highly recommend watching Fireship's list of features for future databases, like branching. Also, if you want to learn about tech in an easy, humorous way, I recommend watching his other videos.
Fireship - 15 Future Databases - Youtube
With that said, see you next year.
Did you enjoy the article? In creating this blog, I drank too much coffee, utilized various tools such as OpenAI's ChatGPT4 for fixing my grammar, Dall-E for image generation, Paint+ for image creation and editing, and finally my trusty Wacom board for drawing. At Recordly, we encourage the use of any necessary tools to expand your knowledge and enhance your creative freedom.
We are currently seeking talented data engineers and data architects to join our amazing team of data professionals! Learn more about us and apply below 👇



