


Written by —

Written by —
SQL is the most widely used database query language by Data Engineers and Data Scientists. We use it day-to-day to do ad-hoc queries, fetch data from source systems and develop new datasets by joining, aggregating and filtering raw data. It's no understatement to say that we spend time tuning SQL queries in data warehousing and platforms. This means that Data Engineers and Data Scientists create and modify several SQL files during their career and their job quality affects all of us, directly and indirectly.
If the SQL is inadequate, we end-users suffer from slow response time. The customer sees that their data product costs a lot to keep up and running because inefficient SQL consumes more additional CPU time (more about this topic in my previous blog). The vendor responsible for the solution is usually forced to stick with a flawed solution because no one understands it (either due to lack of documentation or because of uncommon use of SQL syntax) so well that they dare to rewrite it.
My question is
How does one write bad SQL, and can it be mitigated?
We have automated data pipelines - we don't write SQL by hand
Thanks to templating and automation, the number of SQL DDL, DQL and DML - clauses can and should be automated with DataOps tools. For example, dbt Cloud leverages YAML files to help Data Engineers to automate the creation of SQL tables (models in dbt) and data quality testing (for example, uniqueness of column value without writing the actual SQL).
Because data quality testing is seen as a boresome task usually easily forgotten, getting help with mundane tasks such as testing the NOT NULL value of a column is a time-saving feature. dbt Cloud has even models for helping the creation of incremental loads without the need to modify the data load INSERT INTO -clauses. All of these features of automation help Data Engineers produce SQL that is consistent, easily readable and efficient.
 Automation does not help with the fact and dimension-tables of a star schema. Data Engineers are still required to join, filter and aggregate data to create the necessary tables used in API queries and as the base of BI -reports. Vendors and consultancies usually claim to have solutions solving this holy grail of DataOps, automation of the publish-layer. These solutions tend to rely on "common" models of industry or product-specific tables. The harsh truth is that industries always have minor modifications added to their source systems due to business requirements.
Automation does not help with the fact and dimension-tables of a star schema. Data Engineers are still required to join, filter and aggregate data to create the necessary tables used in API queries and as the base of BI -reports. Vendors and consultancies usually claim to have solutions solving this holy grail of DataOps, automation of the publish-layer. These solutions tend to rely on "common" models of industry or product-specific tables. The harsh truth is that industries always have minor modifications added to their source systems due to business requirements.
An example of this is SAP ERP. SAP ERP implementations have a lot in common between industries, but the company-specific logic is built into custom Z-tables or Z-fields that are added to standard SAP tables. So even though any common model could describe and automate data fetching, for example, logistic process and tables involved in that, a Data Engineer is still required to investigate, understand and fetch the data from necessary custom tables and join those into the final product by hand. So whether you like it or not, the data product or BI report is as good as the SQL skills of the Data Engineer(s) working on your project on that day.
What is a sustainable code?
Bad SQL can be different things for several other people. For example, SQL written for analytic databases should differ from the SQL written for OLTP -systems. SQL that is bad for your database can be good for someone else. There are some traits of bad SQL that are shared between platforms. Typically, bad SQL had some of the following characteristics.
Bad SQL is
• Hard to read
• Hard to maintain
• Executes inefficiency
For me, sustainable code, SQL in this case, is a term for solutions that try to avoid those bad traits listed above. Sustainability can be something else that tries to solely lessen co2 emissions. In this case, a solution used for a long time, maintained by several people and hopefully using less CPU time, is our goal. In this blog, I will go through pointers on how one can write SQL, that is good and sustainable enough to stand for years. We will start digging into this topic by examining the career of Jaromír Jágr.
You are asking way too much
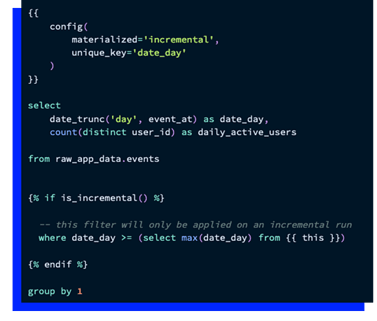
Jaromír Jágr, born in Kladno, was drafted as the 5th overall pick by the Pittsburgh Penguins in 1990. Jaromír started his NHL career immediately at 18, being the youngest player in NHL at the time. There is a legend told, by the man himself, that he did 1,000 squats a day when he was just a kid, and by doing so, he was ready for the NHL at the earliest time possible. The coach of the Pens (Bob Johnson at the time) could have tried to find his player card from the NHL roster database by executing a simple star selection with a simple where clause that filters players who had the most points (in this case, we know that we have a points-attribute in our database table).

Fig 1. example1.sql
|
Assuming this query was executed at the end of the 1991 regular season, it would have returned the names of Wayne Gretzky, Brett Hull, Adam Oates and Pittsburgh legends such as Mark Recchi, John Cullen and Paul Coffey, but not Jaromír's name. With 57 points under his belt in his first season, he was a rookie candidate, but far from 79 points made by another rookie of that year, Sergei Fedorov and far from the performance of the Calder and Vezina Trophy winner of that year, Ed Belfour. Early years at Pens were also hard off-ice at the start because Jágr did not speak English at all. This led Pens to acquire Jiri Hrdina from Calgary so he could discuss in his native tongue, Czech, with someone else. A few years at Pittsburgh ultimately helped Jaromír to settle in and become more known and popular off ice, so popular that he even read the weather report on the local radio station. Coming back to SQL. Besides the fact that the Pens coach could not find the information he was looking for, the SQL query crawls way too much data. It scans the whole NHL table roster, returning players from other teams. Even worse, executing the same query again later on in the off-season could probably return even more data. The person responsible for the roster table might have added new attributes (like average time on ice) or added historical data to the same table (like players from previous NHL seasons). |
|

18th on Most Career Points -list with 1274 GP (DET, STL, BOS, WSH, PHI, ANA, EDM), 780+630=1410 points
25th on Most Career Points -list with 1269 GP (CGY, STL, DAL, DET, PHX), 741+650=1391 points |
The lesson is that do not use 'select * from table', even though you are trying to fetch a small subset of data. The table where you are making the query will most likely change, and your SQL execution time will get longer and longer.
Use column names in the SQL query even though you are searching for a small subset of data. By doing so you can write SQL that will be free of unnecessary odd hiccups in the future and will be more predictable in query performance.
In the next season, our Pittsburgh head coach changed. In the summer, just after the Pens had won their first Stanley Cup, the previous head coach Bob Johnson was diagnosed with brain cancer and was replaced with a temporary head coach.
Johnson ultimately died on November 26, 1991, making the temporary head coach a permanent coach. Pens' temporary head coach was Scotty Bowman, who had gained fame by winning four consecutive Stanley Cups with the Canadiens between 1976 to 1979.
Leave assistance, get good Karma
Assuming Scotty would have tried to find Jaromír's card now, he could have executed the following SQL query.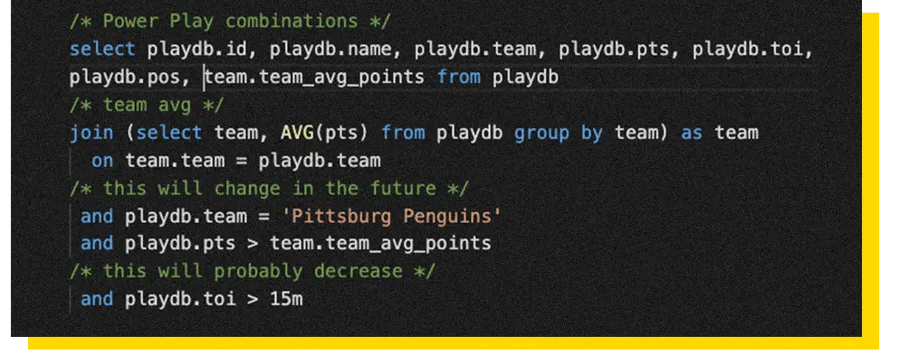
Fig 2. comment.sql
The SQL is lengthy, but it already gives some inside what we are looking for. Because the previous star select had at least a comment, it revealed why the query was made in the first place. SQL was needed to find players who were the 'go-to guys' for the power play. Sometimes even the simplest SQL queries benefit at least from some kind of comments.

Commenting on self-explanatory SQL queries might not be needed, but sometimes the SQL is not understandable even to the writer after several weeks, let alone to a newcomer. The lesson is to embrace commenting if you want to write a SQL that stands time. You'll never know who will read your SQL next time.
This SQL query would stand the time starting from season 1991-92 when Pittsburgh Penguins won the Stanley Cup again, this time as the season dedicated to Johnson. Jaromír increased his points to 69 - and from there, he had seasons after that ending with 94 and 99 points.
Mid 90's at the Pens were a good time for Jaromír outside the ice as well as because (believe it or not) Jágr had his own peanut butter that he said had healed his groin injury.
Local Pittsburgh News Story from when Jaromir Jagr got his own Peanut Butter. - Sean Wilson, youtube.com
Things that are clear to you are puzzles to others
During the 1995 lockdown season, Jaromír, age 22 at the time, returned to his hometown Kladno and visited Italy and the town of Bolzano for excellent point-per-game stats. He also had a brief one-game stint in Germany at Gelsenkirchen where he played for Schalker Haie 87. The team played on the third tier, which meant that the team didn't have the money to cover his NHL grade pay. Jaromír wasn't keen on the money, instead, he opted to play for a "schnitzel with fries and mayonnaise" as long as his insurance was covered. Jaromír scored one goal and made ten assists in the game. He returned back to Pittsburgh after the game as the lockdown was over. During that lockdown season, the head coach of Pens, Eddie Johnson could have made a few changes to the SQL to make it even more understandable.
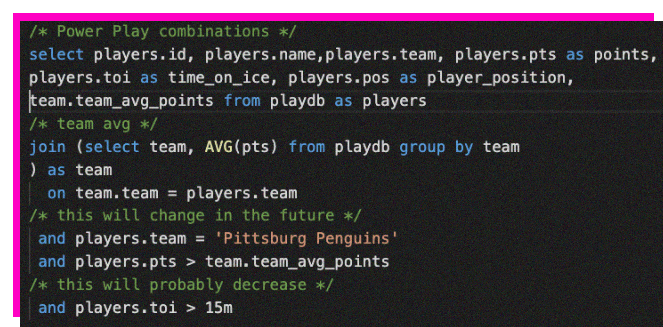
Fig 3. alias.sql
Using aliases is a way to improve readability as sometimes the SQL fields aren't so clear. In this SQL -text attributes are pretty clear from the start and might not actually require aliases, but for example, anyone who has worked with SAP-based sources knows that column names used in SAP are not easily understandable and require translation and clarification. In our case translating hockey-lingo such as "TOI" to "Time On Ice'' might be beneficial someday because using aliases also makes your SQL sustainable, because the fellow after you who is going to modify your SQL query doesn't need to start guessing what the fields are in your SQL query.
Ideally, your SQL should be something that can be reused time and time again. This helps project transfers from person to person or between companies when the base of your data pipelines, the SQL is clear and easily transferable. Remember to use 'as' when you use aliases, it makes the SQL more readable.
In a lockdown season that lasted only 48 games, Jaromír netted 70 points, granting him the Art Ross Trophy, which is given to a player who leads the league in points at the end of the regular season.
Reusability is the key to success
After the lockdown season, Jaromír was on fire. From 1995 until the end of season 2000-01 he netted the following seasons with points as 149, 95, 102, 127, 96 and 121. The last four seasons granted him the Art Ross Trophy again, four times in a row leaving behind such legends as Peter Forsberg, Pavel Bure, Teemu Selänne and Joe Sakic.

190th on Most Career Points -list with 702 GP (VAN,FLA,NYR), 437+342=779 points |

127th on Most Career Points -list with 708 GP (QUE, COL,PHI,NSH), 249+636=885 points |
The end of the season 2001 also ended an odd streak where from 1981 to 2001, only three players won the Art Ross Trophy: Gretzky, Lemieux, and Jágr. As the new millennia had begun, our Pens head coach, Ivan Hlinka, could have looked into his database this time with a fresh mindset and used the following syntax.
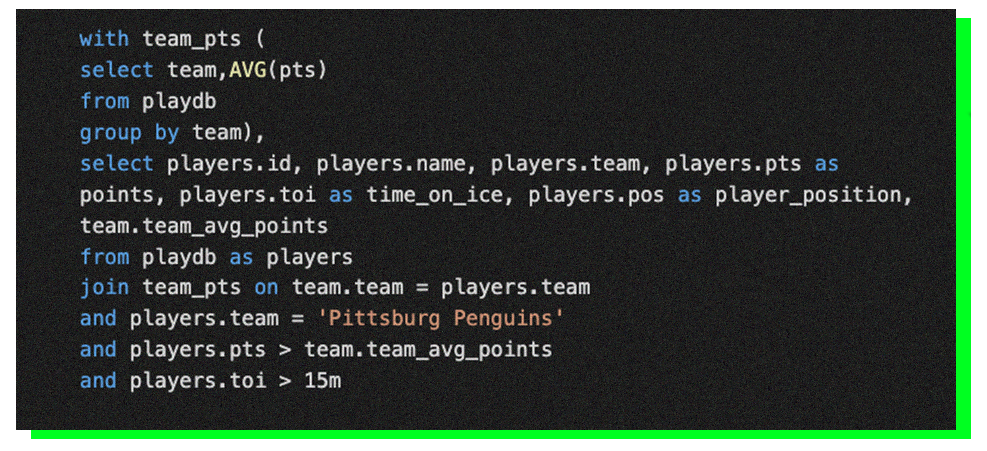 Fig 4. cte.sql
Fig 4. cte.sql
As you can see, the SQL query uses CTE. CTE is a common table expression, a temporary result that exists within the scope of the SQL query and can be referred to later within the SQL, as seen in the example query, as many times as needed. This means that CTEs are an excellent tool when you need to do recursive programming. CTEs make your code much more readable when the code you are writing is split into smaller blocks solving problems one by one.
When your code is readable, it makes maintainability a much easier task. You can't repeat the logic too often - sustainability comes from solutions that can be reused again and again. This means that they should be well documented and easily understandable in addition to the code performance. CTE is an excellent tool for that in SQL -language.

The SQL would have returned Jaromír's name every season, as he was the key player at the time for the Pens. The result set also contained Mario Lemieux, who had made a comeback in 2000. Having Mario back on board, resulting in a situation where Jaromír was no longer the first man in Pittsburgh that he wanted to be and what's even worse, the Penguins were short on cash. At the same time in Washington, the Capitals were trying to create a team that could bring the Stanley Cup into town for the first time. In a surprise tradeoff, Jágr was traded to Washington in an exchange "of nothing". Kris Beech, Michal Sivek and Ross Lupaschuk were sent to Pittsburgh and Jaromír signed a seven-year and $77 million deal with the capital city.
 8th on Most Career Points -list with 915 GP (PIT), 690+1033=1723 points |
 124th on Most Career Points -list with 1081 GP (WSH, OTT, ATL, CHI), 503+389=892 points |
Leave some space
As you might have noticed, the SQL was still pretty ugly even though it performed well and used CTEs. Simple changes, like enforcing the use of indentation and whitespaces can turn your code clearer as you can see below. Using indentation can be also enforced by tooling. For example, many modern IDEs, like Azure Data Studio, provide SQL linting capabilities through the Format Document option. Other options are to use SQL linters like sqlfluff or sql-lint. SQL linters go way beyond enforcing indentation and whitespace rules.
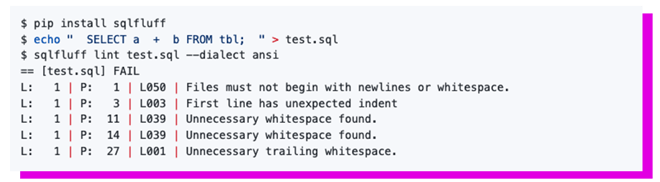
sqlfluff installation as per docs.sqlfluff.com
They provide capabilities to fix your SQL on all levels, as the stuff mentioned already on this blog. I recommend trying out one of those. SQLfluff even provides templates for Jinja and dbt, which means that you could ideally fix your SQL automatically as part of your dbt pipelines.

Fig 5. indentation.sql
What comes to our SQL you can see that the SQL is way easier to read, when indentation is used. Depending on your team's own rules, tabs are either allowed or disallowed. The time at the Caps for Jágr was the time when he tried to find his own space without his former teammates. This time he failed, even though everything looked good on the paper. During his tenure with the Capitals, he failed to defend their previous year's division title and missed the 2002 Stanley Cup finals. A year later he and the Capitals dropped from the playoffs when they lost to the Tampa Bay Lighting. Jaromír's time at Washington was nearing the end.
If we would have run the SQL to the NHL database by now, we would have seen that even with the help of his former linemate and childhood friend from Kladno, Robert Lang, Jágr was really far (pointwise) from his days at the Pens when he netted average 100 points per season (being the good guy he is, Jágr has apologized his time at Washington to Capitals fans multiple times afterwards). With points of 79 and 77, Jaromír was traded to the New York Rangers in the mid-2003 season.

3rd on Most Career Points -list with 1756 GP (EDM, NYR, VAN), 694+1193=1887 points
CAPITALIZE
Building on the previous SQL, we can clean up the SQL a bit more. Readability increases if we capitalize reserved keywords like 'SELECT', 'FROM' and 'AS'. This will further help you to distinguish what attributes you're trying to find. In our case, we are trying to find information about the player points compared to the team average. This time the SQL has a new attribute; age. We want to know how old the player is because NHL players tend to peak their points-per-game performance usually around the age of 25 (as explained in this article). Jágr was pushing 31 years when he joined the Rangers.
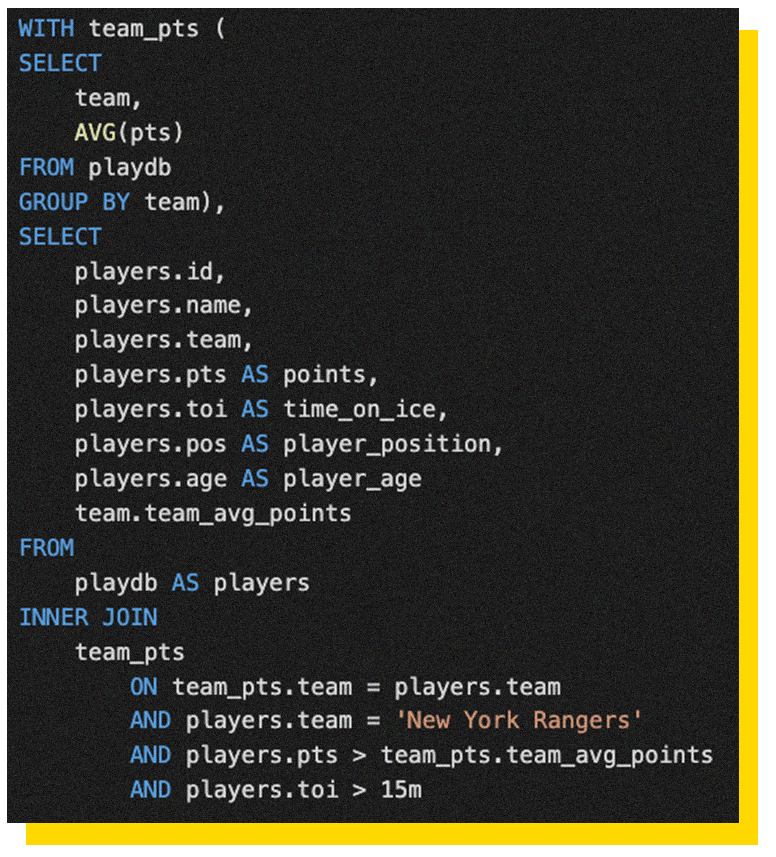
Fig 6. capitalize.sql
In season 2004-05, the SQL would have returned nothing as the league was having a labor lockout. All the players were in European teams, including Jágr at HC Kladno and Avangard Omsk. During this time we could have added more information to the SQL, but because the SQL is starting to look clean and easy to read, the commentary isn't necessary at this point. After the lockout season, Jágr was ahead of the pack. At age of 33, he set new limits that are New York Rangers club records to this day. Jaromír finished the season with 54 goals (Most goals per season) and 69 assists totalling the astonishing number of 123 points (Most points per season).
Club legends such as Mark Messier, and Jean Ratelle are over ten points behind Jágr on the overall points, meaning that the most points record might not be broken anytime soon (Chris Kreider netted 52 goals in the 2021-22 season). Jágr also led the Czech team to a gold medal in the 2005 IIHF World Championship Games and by doing so he entered the famous triple-gold club, having won the Stanley Cup, World Championship and Olympic gold in 1998 in Nagano. Although everything looked good again for Jaromír, the Rangers didn't get past the conference semifinals in years to come (not until season 2011-12). Jágr was also well known to international ice hockey fans as well, because he participated in 10 IIHF Ice Hockey games (2 wins, 1 bronze), 5 Olympic Tournaments games (1 win, 1 bronze) and twice at the World Cup of Hockey (1 bronze).
Here he have Tuomo Ruutu tackling Jaromír Jágr at 2011 games - MentHos, youtube.com
Pre-agreed naming conventions make your life easier
This might not sound much, but having pre-agreed naming conventions makes everybody's life so much easier. If you agree beforehand that when referencing multiple tables in your SQL you write the name of the referenced table in full. Let's say that you have a countries - table, containing master data of country and region, you reference the table as countries within your SQL. Not cnt, c, country or something else like the original table name in your ERP. Just countries. It makes debugging much easier when you can see that original table name or the CTE name right away.
This is an example of a pre-agreed naming convention and if you make those within your team, I guarantee your life will be much easier. Sometimes though, your plans don't go like you would like them to go. For this reason, we are adding new CTE into our SQL to help identify where the player is currently playing based on the country code each player carries each season. Notice also how easy it is to identify parts of the SQL with the help of well named CTEs.
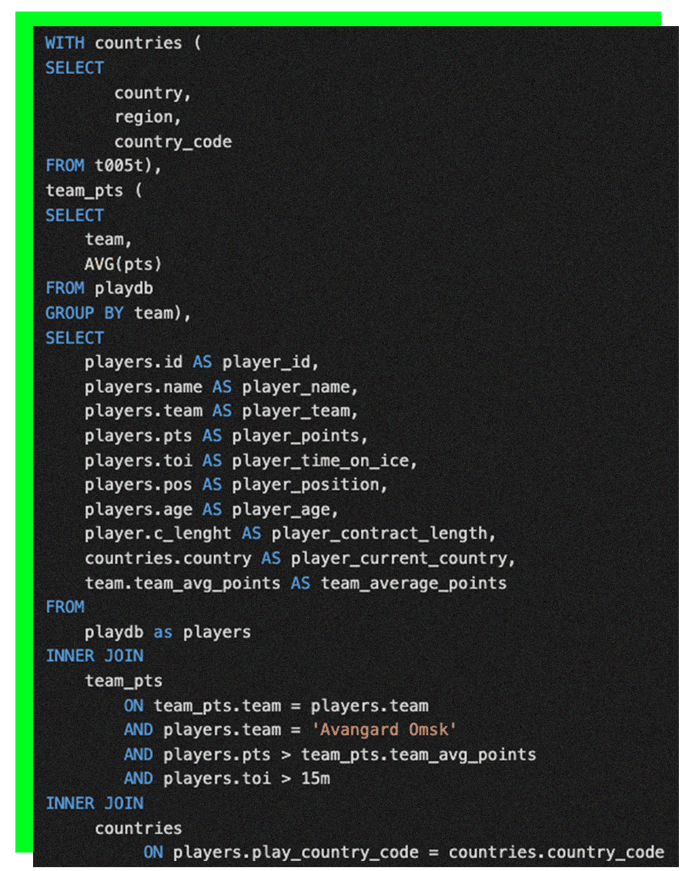
Fig 7. location.sql
The real reason we're adding this country location is that after years in New York, Rangers general manager Glen Sather opted not to continue Rangers's captain, Jaromír's deal at the end of season 2007-2008. Jágr was an unrestricted agent for the first time in his career, but he did something that is still considered a rather odd move because he was offered NHL deals from other league teams and as we know by now, he may have topped Gretzky’s goal-scoring record if he had stayed in America. Jágr went to play for three seasons in the newly formed Russian Continental League with Avangard Omsk. With that move, we can also say that our SQL is as good as it gets. The final touch that we do is to include prefixes for ambiguous column names, like id, name, and team in our SQL. If we add the "player" -prefix, it helps us to identify that the id is clearly a player_id.

1st on Most Career Points -list with 1487 GP (EDM, LAK, STL, NYR),
894+1963=2857 points
Are mullets back in style?
Style guide? Handbook? Handbooks and style guides are trademarks of mature teams and you start creating one as early as possible. Having pre-agreed naming conventions, rules and boundaries written down helps new team members to come into your team and reduces mistakes in the long run. The handbook should be ever-evolving and can for example contain chapters dedicated solely to SQL conventions. The Internet is full of good references for handbooks. I recommend looking into SQL Style Guides made by Gitlab and Mozilla Foundation, which I have also used for inspiration for this text.
The honest truth is that good style never goes out of fashion. In our case, the mullet was back. On 1 July 2011, Jágr returned to the NHL with a one year contract with Philadelphia Flyers. This marked the start of his last leg (to this date). During his time at the NHL, Jágr touched many fans and great example of this Traveling Jagrs. Traveling Jagrs is a testament to how one can start something with pre-written handbook rules, like the SQL Style Guides for us adding new members to Traveling Jagrs was made easy. Just wear a Jágr jersey, hockey socks and fake hair to the game and support Jaromír. The group got really big because Jágr played for 9 teams in the NHL between 1990 and 2018.
Jaromír Jágr – entertain the fans in Calgary - Merlun Recut, youtube.com
During the period 2011-2013, he also played for Dallas Stars and Boston Bruins scoring good points-per-game stats, but no longer netted the points he had done previously. Funny story about his time in Boston is that Jágr went on TV and he was asked who his favorite player was. His response was as unexpected as it was awesome. His answer was himself. The season of 2012 also saw yet another lockout and during that period Jaromír played for his home team Rytíři Kladno.
Learn to analyze devilish execution plans
You might be familiar with the situation where you write good SQL (or at least you think it is good), but the database executes the SQL slowly. It might be that you have used SQL syntax that has worked well in different database engine that you'd assume that it should work here as well. The reality is that database engines execute the SQL differently depending on the execution plan. Luckily most modern database engines provide a graphical interface to see how your SQL is dissected and executed. UI's can even provide you with an insight into what is the most consuming part of your SQL.
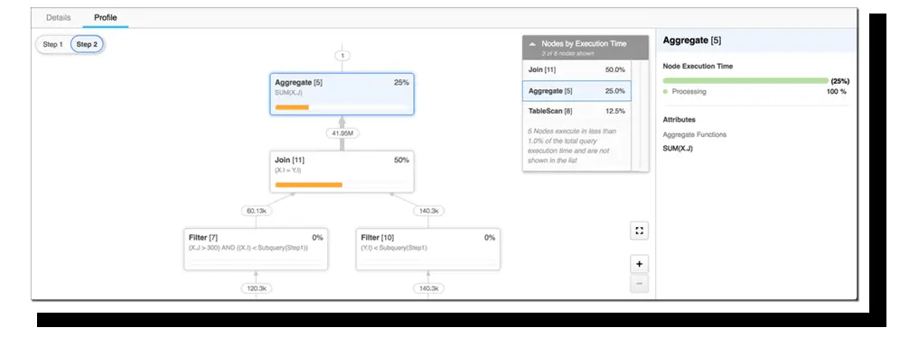
Analyzing Queries using Query Profiler - docs.snowflake.com
After learning how to play again in the NHL, Jaromír signed a one-year contract with the New Jersey Devils. A sign of mistrust was already placed on his age, as the one-year contract included $2 million as an incentive bonus if Jágr was to play in at least 40 games. When you know how to play the game you can make your own execution plans. At 41, Jaromír finished the season as the leading scorer with 67 points.
This led New Jersey Devils to sign him for another season. At his age, 67 points would have gone down in history as one the best season made by players over 40 (if he had not outdone himself later on). Seasons at New Jersey were tough as the team failed to qualify for the playoffs on both seasons. Jágr kept breaking league records and on the second New Jersey season, he became the oldest player in NHL history to score a hat-trick at 42 years and 322 days. Ultimately Jaromír was traded to Florida on 26th of February 2015.
ISO (ANSI) SQL is your friend
Generic SQL is a topic which sometimes raises grey hair. What generic SQL ultimately stands for is a way to write SQL without using database engine-specific functionalities. Sometimes this sounds really stupid. Why would I write SQL that doesn't take advantage of all the functionalities of my backend database? The reason is portability. Like with Jaromír, you have your style of play that works everywhere, no matter the teammates. For Jágr, it was all about using his size, which enabled him to protect the puck in such a manner it gave him the advantage over others and thus enabled him to slow the game down. So when writing SQL, try to stick with ISO/IEC, commonly known as ANSI SQL, rather than learning the intricacies of T-SQL (Microsoft variant) or PL/SQL (Oracle variant). ANSI SQL has come long and is now on the 8th revision (SQL:2016).
I recommend from time to time trying to see whether your favoured SQL functional written either in Oracle or PostgreSQL proprietary can be refactored to use the ISO alternative. For Jaromír, his playing style still worked in the 2015-16 season in Florida. Panthers qualified into playoffs (although dropped at the first round against Islanders), and Jágr (at the age of 44) was the best scorer for Florida Panthers with his 66 points surpassing Jussi Jokinen, 32 years and 60 points and Alexander Barkov, 20 years and 59 points.
Common data types are also your friends
As with the generic SQL, using ANSI SQL data types is to your benefit. In the case of Snowflake DECIMAL, NUMERIC, INT, and INTEGER are all synonymous with the Snowflake NUMBER datatype. This doesn't mean that one should start using NUMBER datatype in all your SQL. The NUMBER datatype is specific to Snowflake (and Oracle).
Even though I see Snowflake as a product of the future, I still understand that new contenders can arise at any time. Using ANSI SQL data types provides easier portability. Here is a list of well-known data types and their ANSI SQL counterparties for your guidance: https://nils85.github.io/sql-compat-table/datatype.html
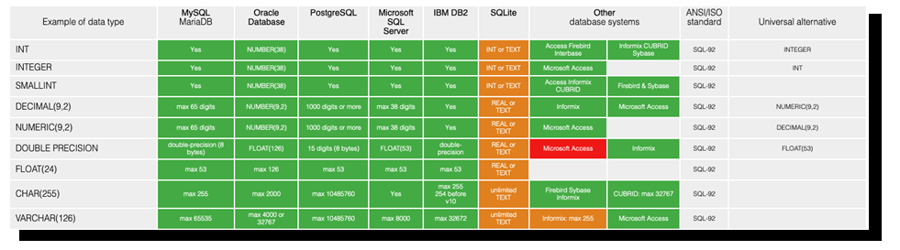 Data type compatibility list provided by nils85.github.io
Data type compatibility list provided by nils85.github.io
Jaromír also got one more chance. He signed with the Calgary Flames as he had wanted to experience what it was to play in a Canadian team. Although the season started good, Jaromír's injuries limited him to career-low seven points in 22 games and he was placed into injured reserve on 31 December 2017. On 28th of January, Jágr was placed on waivers, which meant that his career ended in the NHL as he cleared the waivers with no-one picking him up.
On February 2018, Jaromír returned to his home team Rytíři Kladno where he still plays to date, being one of the key players of the team together with another Rytíři Kladno alumni Tomas Plekanec and being the role for model for everybody at Kladno as he is the majority owner of the team.
Wrap-up time
As you might have noticed, multiple ways exist on how one can improve SQL writing skills. No one is born a master. Your SQL writing skills will improve over time. By now you might be wondering why on earth I included Jaromír Jágr in the mix?
The reason is that Jaromír is living proof of sustainability. When the groundwork is done correctly, you can have a career that will last a long time.
Something that most written SQL today should try to accomplish. Write an SQL that will stand the test of time. Write it so well that you can use 10 or 20 years for now. Write it so well that it is self-documented. Write it so well that your mother can understand it. Write it so well that after several years you can understand it. Write it so well that you're proud of it. That's the level Jaromír has accomplished in his career.
At the age of 50, he is still a valid contender for new players and still holds the record of having second-most points in NHL history, after Wayne Gretzky (I know that Jaromir is now finally hinting that he might end his career). Good groundwork will always reward you in your later life. Whether writing SQL that you might be facing years later or training to be one of the greatest ice-hockey players that have skated on the surface of the earth.
2nd on Most Career Points -list with 1733 GP
(PIT, WSH,NYR,PHI,DAL,BOS,NJD,FLA,CGY), 766+1155=1921 points
Disclaimer: The pictures seen in this written piece are my old ice hockey cards, which I painstainkily reshot and repurposed for this written piece are used here educate people, meaning that all content and information on the website is for informational and educational purposes only.



