
Written by —

Written by —
THE CHALLENGE
Between November 20th and December 18th of 2022, 22nd FIFA World Cup is played again.

Every one of us has some opinions on which team is the best. For me, it's Italy. I was born in 1984 and my brother was born a few years later, in 1986. For me and my brother, the games held in 1994 were the first games that we truly remember. At that time, you kinda chose a country to root for in the games, as Finland wasn't participating. I chose Italy because of Roberto Baggio and my brother chose Brazil. I'll leave that to sink in for those who remember when the games ended in the States.
Now that I'm heading into my 40s, I'm still interested in WC games but I know more about how data can help in predicting outcomes and I know a bit of SQL and Python. Can I predict the outcome of 2022 games using already existing data, my skills and a platform called Snowflake?
In this blog post, I will go through the tools used in the ML pipeline, go through the pipeline step-by-step, show my prediction of the FIFA World Cup winner of 2022 and lastly discuss how one can create production ready ML pipeline together with dbt.
THE PREMISE
This will be the last time when 32 teams will attend the games, next games will be joint games with Mexico, Canada and the United States in 2026, and those will have 48 teams attending.

Teams are divided into groups from A to H (8 in total), from which the two best teams advance to the knockout stage. For me, this means that I need to calculate the outcome of 64 games.
For that, I need the help of Machine Learning. Luckily, for "some" reason, predicting the outcomes of football games is popular in betting groups and there are multiple good articles on predicting the outcomes of Premier League games.
Inspired by those articles, I will also apply the popular Poisson distribution formula to calculate game results. I already know that the Poisson distribution has its flaws and better results would be achieved with Dixon-Coles or further more with a Bayesian model. In this case, I will stick to Poisson as the main purpose of this article is to demonstrate how Snowpark and Python UDF capabilities elevate the Snowflake ecosystem to support Machine Learning use cases.
For those who are unfamiliar with statistical models, the Poisson distribution formula is a model that can be used to give a probability for events which are not related to each other (editors note: this is highly simplified). In this case, it will give me the probability of home wins based on existing data from previous football matches.
As data, I will use a dataset provided by Kaggle which contains results of over 40,000 international football games from 1872 to 2022. This dataset contains information on when the game was played, where it took place and how it ended. To avoid odd results, I will limit the data to results from 2000 to the present. All of you with knowledge of football history can already guess that using data from the early 1900s would change results highly in favour of previously dominant countries, mainly England (sorry for fans of England, the cup is still not coming home).
THE ML PIPELINE
The pipeline that I'll be using to predict the results of the WC games, is the following and has the same traits as in Snowflake release blog about Python for Machine Learning.
- Load data from Snowflake into Snowpark
- Train a model using data provided by Snowpark
- Create a Python function to predict game results based on model
- Upload Python function into Snowflake as Python UDF
- Create For Loop with Snowflake Scripting to use Python Function
As you can see, I will not test nor retrain the model in this example. The main purpose is to show the process to show how easy it's to a create trained model and call it inside Snowflake is where normal SQL code. All the code shown here can be found in its original format on my GitHub account.
THE TOOLS
SnowpARK

Snowpark is a library which provides an API to query and process data inside Snowflake.
Snowpark has similarities with Spark, but with the difference that Snowpark supports pushdown for all operations, including Snowflake UDFs and it doesn't require separate clusters outside of Snowflake for computations. All of the computations are done within Snowflake.
With Snowpark you can build data frames and such either with familiar SQL statements or with methods such as select to fetch all data inside a table inside Snowflake. With Snowpark all operations are executed lazily on the server, which reduces the amount of data transferred between your client and the Snowflake database.
SNOWFLAKE
SCRIPITING
Snowflake Scripting allows users to create structures and control statements, such as conditional and loop statements and makes it easy for Snowflake users to create stored procedures and translate existing SQL-based scripts.

With Snowflake Scripting you can create familiar IF, CASE, FOR, WHILE and LOOP statements.
Snowflake Scripting can use a cursor to iterate query results one row at a time and with the combination of Functions you can create, for example, stored procedures or pipelines that call a SQL (Python/Java) function in a WHILE loop.
PYTHON UDF
Python UDF is Snowflake User Defined Function that allows the user to write Python code and call it inside Snowflake as if it were a normal SQL function.
Python UDFs are scalar functions; for each row passed to th e UDF, the UDF returns a value. Python UDFs can contain both new code and calls to existing packages, allowing you both flexibility and code reuse. This means Python UDFs enable the user to train an ML model, upload that to Snowflake and call a Python function referencing a trained model. The partnership that Snowflake made with Anaconda allows Snowflake users to use 3rd party packages in Python UDFs and Anaconda handles everything you out automatically, like performing dependency management of packages and installing the required dependencies. Python UDFs are currently on Preview Feature -state and Open to all accounts.
e UDF, the UDF returns a value. Python UDFs can contain both new code and calls to existing packages, allowing you both flexibility and code reuse. This means Python UDFs enable the user to train an ML model, upload that to Snowflake and call a Python function referencing a trained model. The partnership that Snowflake made with Anaconda allows Snowflake users to use 3rd party packages in Python UDFs and Anaconda handles everything you out automatically, like performing dependency management of packages and installing the required dependencies. Python UDFs are currently on Preview Feature -state and Open to all accounts.
THE STEP-BY-STEP PROCESS
Load data from Snowflake into Snowpark
The first step in our ML pipeline is to load data from Snowflake into Snowpark.
Because Snowpark is still a separate API from Snowsight, I need to use Jupyter Notebook. Inside Jupyter, I will need to import the necessary Snowpark packages.

The session command is used to create a connection to Snowflake and the functions package is needed to wrap up my Python code that it can be uploaded back to Snowflake. Establishing the actual connection is straightforward, you define the necessary parameters. Bear in mind that this schema is also the location where the end result (code with trained dataset) will be stored.
I also need to install the necessary Python packages that are needed to create my Poisson model. For these I need to make sure that the packages do exist in the Snowflake Acadonda 3rd party support list. There is a possibility to upload your own packages into Snowflake, but you need to check the possible limitations before importing.
Train a model using data provided by Snowpark
Once we have the connection established, we need to download our training data into Snowpark. We could use Snowpark DataFrame, but we transforming the dataframe right away to Pandas DataFrame. In the end, it doesn't matter, as our use of Snowpark and DataFrames is really limited in this use case.
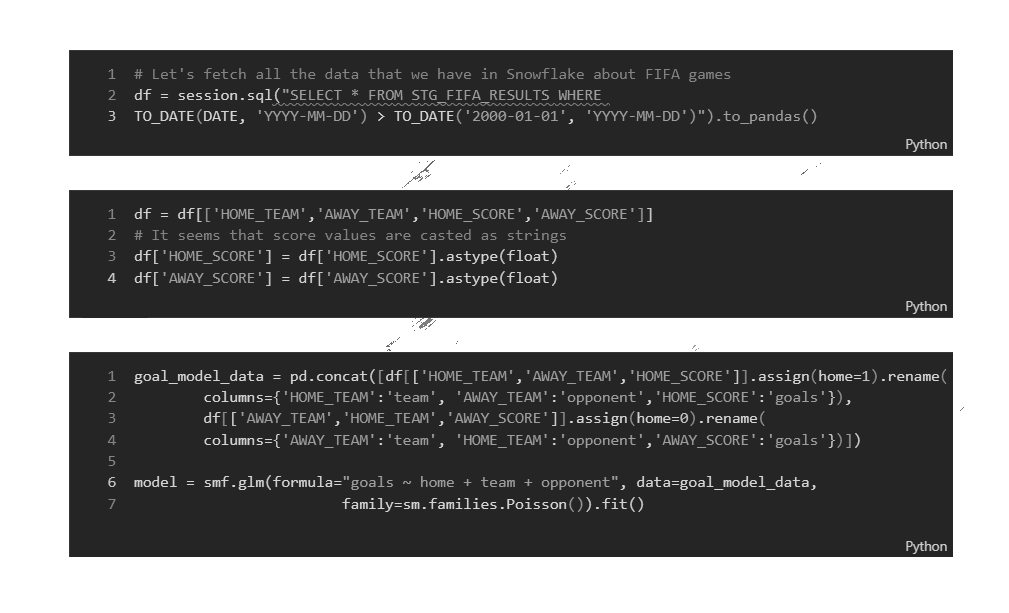
In this case, I'm doing a simple SELECT clause with the clause as STRING, but Snowpark API provides a select method that you can use to specify the column names to return.
|
The whole idea of Snowpark is to better support pushing down SQL or Python commands into Snowflake virtual warehouses. You don't need separate compute clusters to do the calculation. All of the executions are done either locally in your development environment or by using Snowflake Virtual Warehouses. The API includes even commands to scale virtual warehouses as part of your ML pipeline allowing you to scale computers when needed. This is quite an improvement to the fixed model used by Spark where you define the compute resources beforehand. Snowflake has now added also Snowpark-optimized warehouses which provide 16x memory per node compared to standard virtual warehouses. Most likely we will see GPU -nodes in the future as well. In the next step, we will transform the datatypes into floats from varchars. For conversions, Snowflake provides a mapping table. Now we finally get into the chapter where we build our Poisson model which will return 
the expected average number of goals for that for home and away teams. The model we will save as Snowflake STAGE -object using session.collect(). We will be referencing this stage later on. The stage object will be saved into the schema which we defined in the connection string. |
Create a Python function to predict game results based on model
Using the information in the STAGE -object we can build a Python function, which will return an of the probability of the home team (rows of the matrix) and away team (matrix columns) scoring a specific number of goals. This can then be used with basic matrix manipulation functions to calculate the probability of a home win.
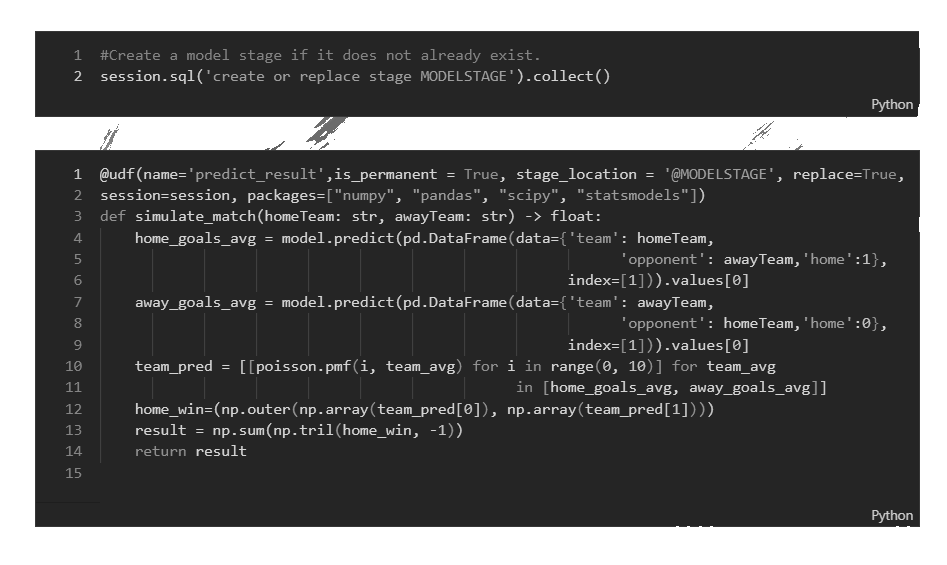
Upload Python function into Snowflake as Python UDF
The whole Python function is wrapped around the Snowpark UDF function (the @UDF -syntax), which will save the code into Snowflake. As you can see, in the command I define the location of the trained model and I also list the necessary Python packages to run the code.
The code itself will be shown as a ZIP package inside Snowflake under Functions.
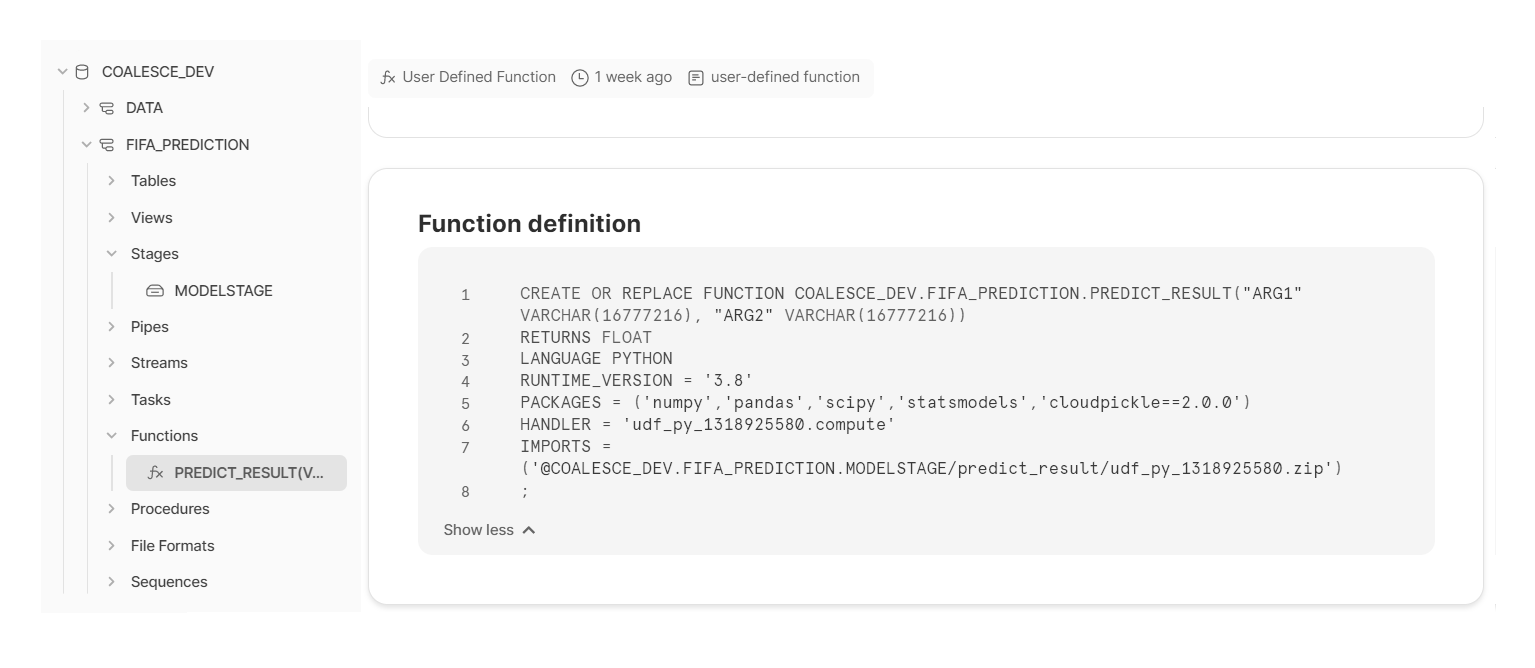
Create For Loop with Snowflake Scripting to use Python Function
|
|
Using the Python Function is the same as using a normal SQL function. You enter arguments and get the result back, in our case the result of the winner of the given teams.
Instead of calling the function manually 64 times, we can create a FOR LOOP using Snowflake Scripting. Our function will take teams from a predefined game schedule and later on the winner's previous round (like in the image), loop the table and UPDATE the table with information about the winner.
Looping through the table happens by declaring a CURSOR which contains home and away team information. These are then used as input records for the function.
THE PREDICTION oF FIFA WC 2022 WINNER
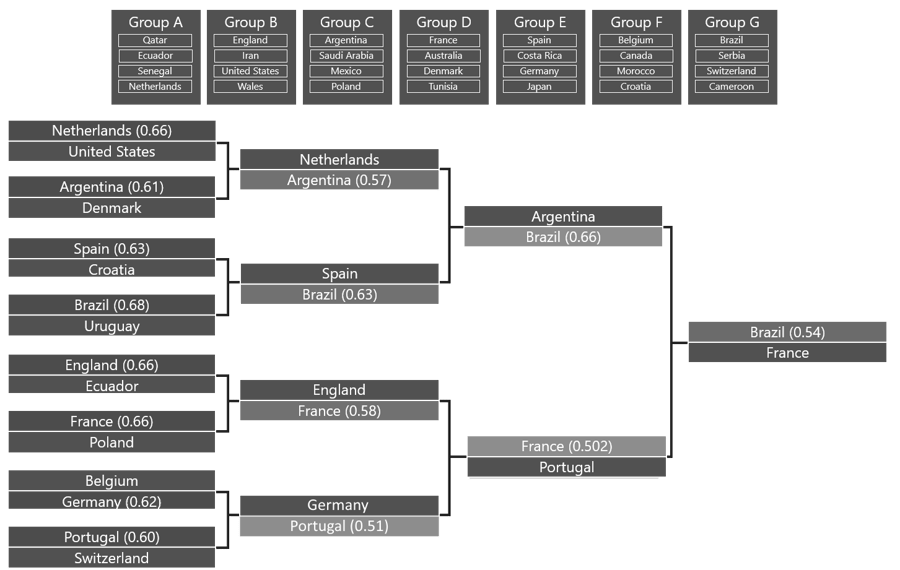
What results did then I get for the prediction of the FIFA World Cup 2022 Winner? Below you can see a chart containing the Groups and countries allocated to those. The results of those can be read from the left. The winner of each game is colored and given a prediction number for the win.  As you see, the matches in the Round of 16 are already really tight, but some clear winners are seen even with general knowledge. Some of the games, like the one between the Netherlands and the States can be predicted without ML (at le.
As you see, the matches in the Round of 16 are already really tight, but some clear winners are seen even with general knowledge. Some of the games, like the one between the Netherlands and the States can be predicted without ML (at le.
If chart the really happens, then we are in a treat for exciting games. According to this prediction, the final match will be between France and Brazil, with Brazil taking the crown in this prediction.
According to Google, these countries are also the biggest candidates to be in the final match (pred 1, pred 2, pred 3) by others making predictions about the biggest sporting event of 2022.
Update 3.12.2022
As everybody has noticed, the games in 2022 have been full of surprises. No one could have predicted Belgium or Germany dropping off after the first round or how well Morocco and Japan have been performing. These surprises have left dents into my previous prediction that my overall hit rate was just above 56%.
What could I have done better? The biggest issue in my ML -model was the lack of ties due to my laziness. I could have easily added code to determine game ties but left that out. Would the ties though affect anything? I looked manually into the results and my hit rate would have been around 65%, so the chart would have been still way off.
Now that the first round is over, I took the game pairs from the official results and rerun the ML -model. It seems Brazil is still going to win, but the final is going to be against Spain instead of France and according to Mr Poisson, it's going to really be even. Otherwise, the chart is still really similar to the previous but now knowing the strengths of each team, I really disbelieve that for example Morocco , is going to lose so easily to Spain or that Japan is going to lose to Croatia with big numbers.
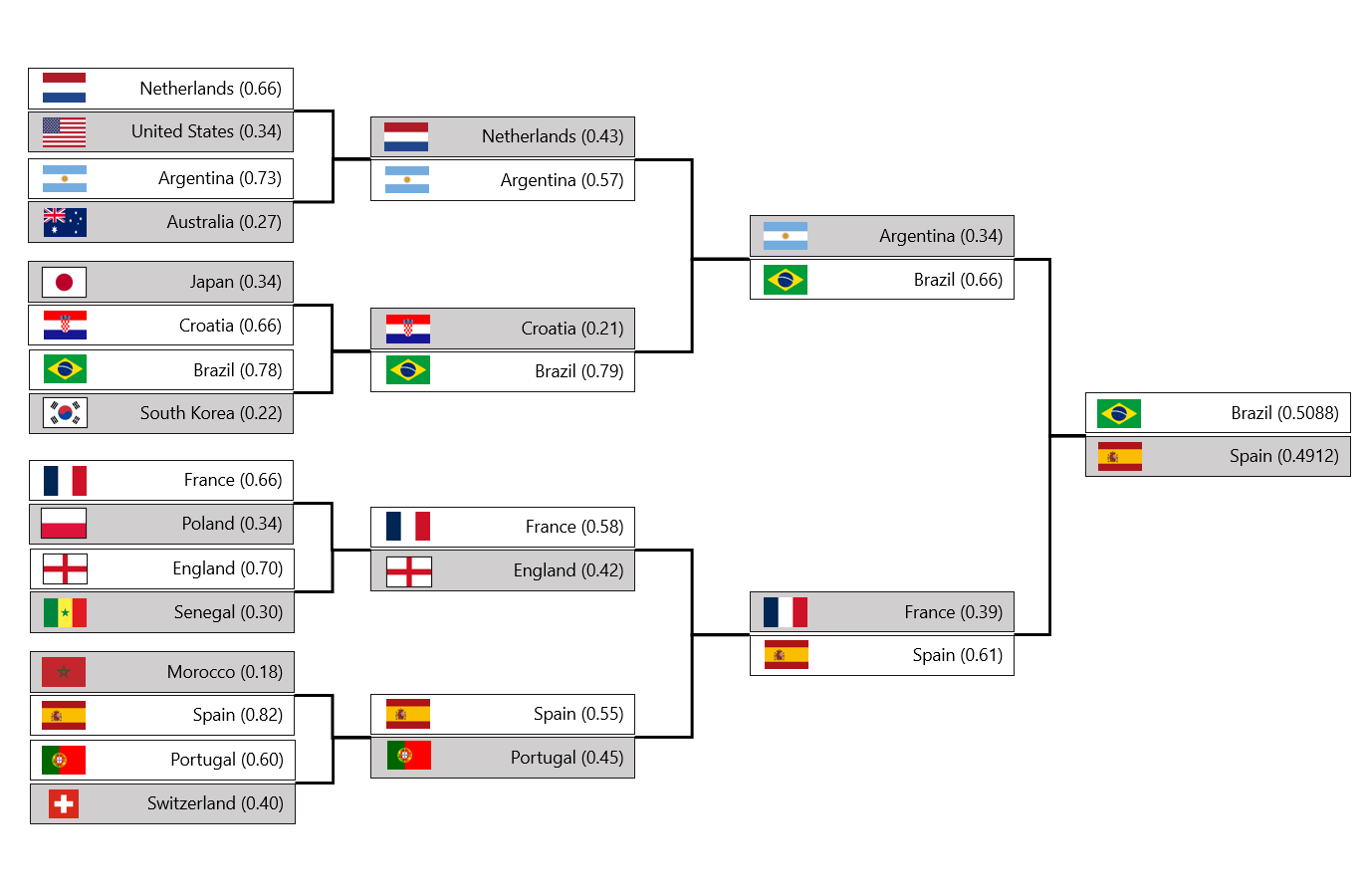
UPDATE 8.12.2022
In my previous prediction, I speculated whether Morocco would lose to Spain so easily. This is due to the fact of knowing how Morocco had actually played versus the data prediction. I was on the right trail for that, Morocco surprised us by winning Spain and thus revamping the chart again. All in all, the prediction rate was already a pretty good one, 7/8.
Luckily this ML pipeline could be run fast to reflect the changes and here's the latest prediction which is somewhat similar that the original. Interesting the next is that for example Morocco and Portugal have faced each other 2 times before 2022, in 2018 and 1986 with wins being tied. This means that there isn't much data on how the games will actually end. On the hand, England and France have faced 31 times before 2022 starting at already at 1923 with England leading on wins at 17-5-9. In the last decade, the games have been mixed with France leading 2-1-1 on wins which might indicate a tight match.
For other games, Netherlands and Argentina have faced 9 times before 2022 starting in 1974 with the Netherlands leading on wins at 4-3-2. Argentina tough won the latest game in 2014. Croatia and Brazil have faced 4 times before 2022 starting in 2005 with Brazil leading on wins at 3-1-0. In 2018 Brazil won the game in St. Petersburg 2-0.
![]()
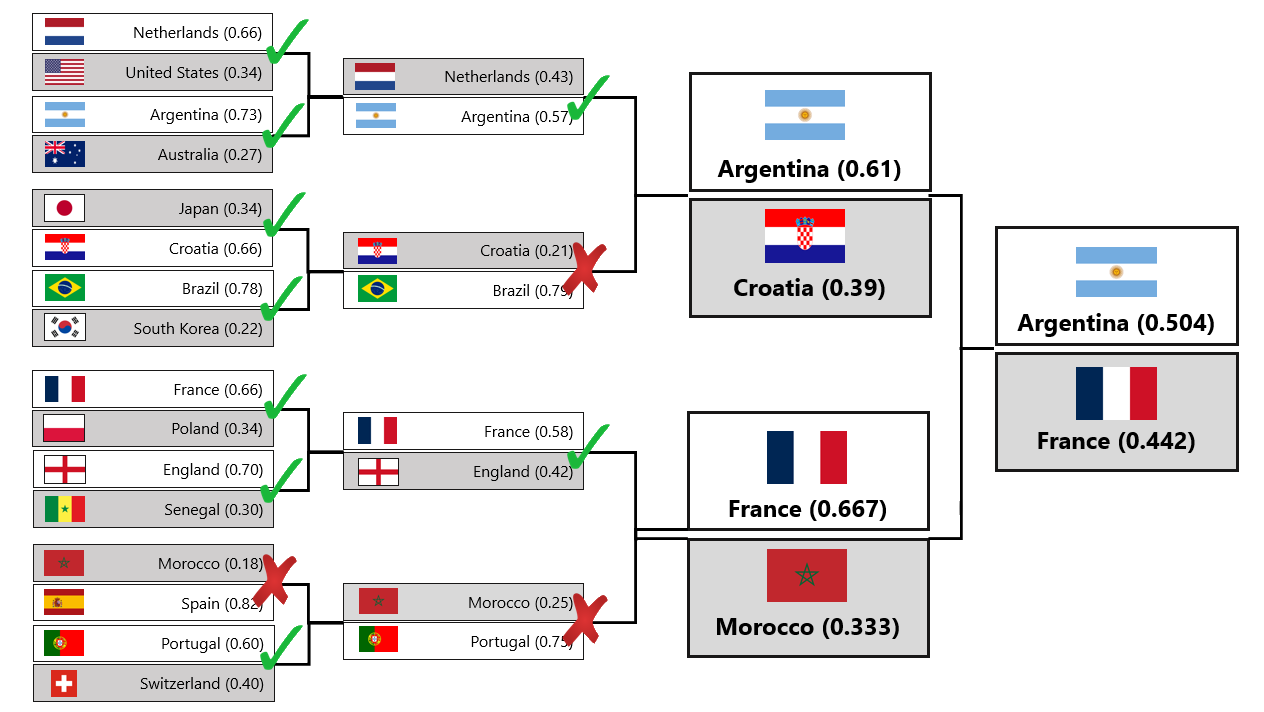
Update 11.12.2022
Morocco keeps fighting against predictions and Croatia gave us a big surprise by winning the match against Brazil. With these changes, as Brazil is no longer in the games, Argentina has risen as the favourite for winning the whole tournament.
THE PRODUCTION VERSION -
MOVING FROM POC TO PROD WITH DBT
dbt Labs announced a few weeks ago in their Coalesce -conference that dbt supports now Python and bypath they mean that clients of dbt Core and dbt Cloud having version 1.3 can run Python code to certain data platforms (Snowflake, BiqQuery and Databricks) with boundaries and ways of working that each of them set on running a Python code.
In our use case dbt executes Python commands inside Snowflake either as User Defined Functions (UDFs) or User Defined Table Functions (UDFTs). For example, creating our model used in the ML pipeline happens by defining the following for dbt.
def model(dbt, session):
dbt.config(
materialized="table",
packages=["pandas", "numpy", "statsmodels", "scipy", "joblib"]
)
goal_model_data = dbt.ref("goal_model_data").to_pandas()
model = smf.glm(formula="goals ~ home + team + opponent", data=goal_model_data,
family=sm.families.Poisson()).fit()
session.sql('create or replace stage MODELSTAGE').collect()
model_file = '/tmp/model.joblib'
dump(model, model_file)
session.file.put(model_file, "@MODELSTAGE",overwrite=True)
return goal_model_data #We need to always return a DF from dbt Python
As you can see, the code does not change. dbt just offers ways to automate the deployment and execution of Python code as it was normal SQL. This allows us to use everything that's good in dbt's SQL deployments in Python deployments as well. Deploying and version controlling an ML pipeline for a use case that can't be solved with traditional SQL is now easier than ever. That doesn't mean that it's yet fully polished.
While creating the pipeline in dbt is simple enough, there are still some major caveats. This is expected when working with brand-new shiny stuff. At the moment, you can't register a UDF from a dbt Python model in Snowpark. You need to do this from a SQL macro or something else: https://docs.getdbt.com/docs/building-a-dbt-project/building-models/python-models#udfs
- Should Python functions be included in dbt entities? Join the discussion: https://github.com/dbt-labs/dbt-core/discussions/5741
Some things that "just work" with Snowpark, don't with dbt Python. This comes down to some design choices dbt has made (which do make a lot of sense from dbt point of view)
- dbt Python is run as anonymously stored procedures (https://docs.snowflake.com/en/sql-reference/sql/call-with.html)
- All dbt Python models need to return a Dataframe, and will result in a table or incremental materializations (NOT ephemerals for example for circumventing this)
In conclusion, running the pipeline in production using only dbt-managed entities is not yet completely production ready. Managing the UDF, and storing and moving the trained model is not a nice developer experience at the moment, and involves a lot of trial and error, and some parts which are just much easier with another tooling at the moment. That said, bringing SQL and Python together in dbt really brings a lot of opportunities, and closes the gap between advanced data science python data developers and SQL data engineers.
The Sustainable SQL Factor
Previously I wrote an article about Sustainable SQL explained with Jaromír Jágr (the image is a link to the actual blog post).
where I explained writing sustainable SQL or any code means that you need to write SQL that is
- Easy to read
- Easy to maintain
- Executes efficiently
Looking at those points, how well does the Snowpark + Python UDF + dbt Combo + Snowflake Scripting combination then perform? Starting with easiness to read, the situation depends highly on your deployment model. If you write the code without using Git integration or just by using Snowsight or any SQL tool (think DBeaver) you'll end up writing code that is hidden from plain sight after initial deployment. If you instead use dbt which supports the dbt-python packages, the situation changes. What was hidden, is visible again and the code is easy to read again. The same rules also apply maintainability. Even though there are still growing pains with this model, it's better to start using tools that support Python deployment from the get-go i.e. dbt.
For efficiency, I can't recommend these Python UDFs for use cases where the Snowflake warehouse used to run the Python UDF is stopped often. This is because Python UDFs are loaded into the warehouse during execution and this process slows down the query which uses the Python Function. There are patterns to avoid this, but running Python UDFs are still resource-consuming until a better pattern for loading the Python packages is created.
THE CONCLUSION
The addition of Python UDFs to Snowflake allows users of Snowflake to solve problems inside the database which were previously hard to accomplish with basic SQL. Python UDFs and Snowpark are still in their infancy and I expect that once Snowpark is integrated fully into Snowsight, the amount users will increase for both capabilities. I hope that the execution issues would be solved with some control method to ease the slowness at first deployment.
All in all, I see Python UDF and Snowpark as a good addition to the Snowflake platform as these features allow users to solve more complex business cases or solve problems that require ML capabilities. I am also eager to see what functionalities together with Hybrid Tables or with Dynamic Tables could Python help to solve as these features bring Snowflake more into the OLTP world and combining OLTP with ML capabilities sounds really interesting.
Interested?
We, here at Recordly, do not simply stop at POCs. We can do those as well, but our goal is to create fully-fledged ML pipelines that can be used in production. We have extensive knowledge of how to build ML pipelines using Snowflake, dbt, Databricks, and Google Vertex AI. Contact us if you have a use case that you would like to put into production.




