Written by —

Written by —
Introduction and Motivation
In the evolving landscape of natural language processing (NLP) and with the emergence of RAG solution patterns, businesses are increasingly leveraging embedding and reranking models to enhance user experiences, optimize search functionalities, and extract meaningful insights from textual data.
Although there are numerous embedding model benchmarks available for English, such as the MTEB Leaderboard, the lack of benchmarks for non-English languages poses a challenge for teams building these RAG solutions.
After coming across a few blog posts that showcase evaluations in non-English languages coupled with a promising starting point provided by the article Boosting RAG: Picking the Best Embedding Reranker Models", I decided to delve into benchmarking for Finnish.

EVALUATION DATA CREATION
I selected datasets from the Finnish-NLP Huggingface organization for the evaluation, including Finnish Wikipedia datasets accessible from this link. Additionally, I chose to perform these tests on a private journalistic dataset to enrich the diversity of the data used in the evaluation.
For a comprehensive evaluation, each dataset underwent two rounds of testing, each with varying document sizes. The first round comprised 500 documents, while the second involved 1000 documents. From each document, I filtered the data to retain up to 256 words, ensuring a manageable yet representative sample for analysis.
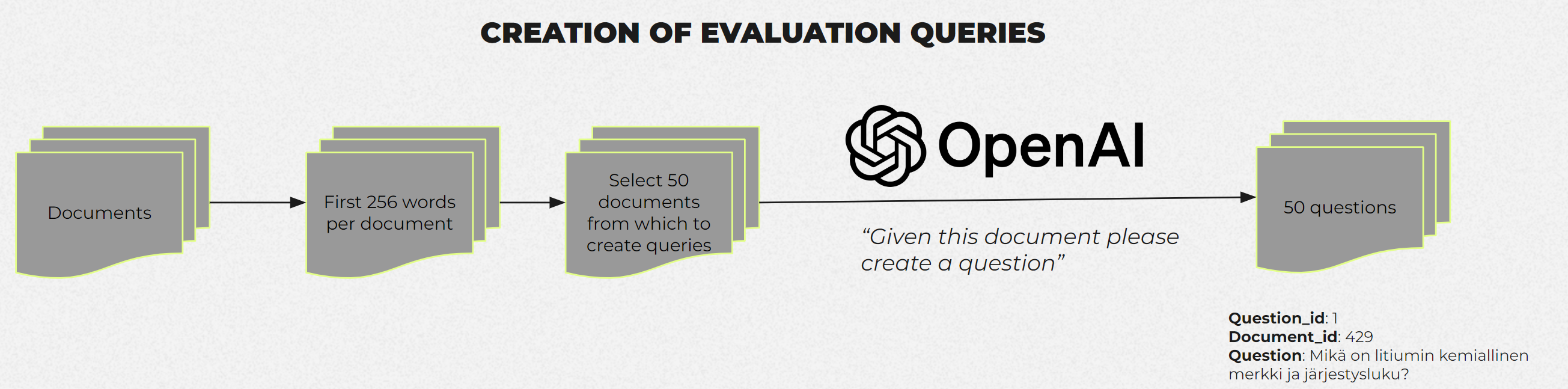
I employed GPT-4 to generate 50 questions for each evaluation dataset. These questions were generated from a random selection of 500 or 1000 documents, providing diverse and contextually relevant queries for assessing the models' performance. In the real world, one might ask the users to form typical queries that they assume they would write to a system like this. The option to add manual questions to the dataset is in the notebook I used but for these tests, I solely relied on the questions created automatically with gpt4.
Embedding models
Embedding models have gained considerable attention, particularly with the emergence of retrieval-augmented generation (RAG) solutions.
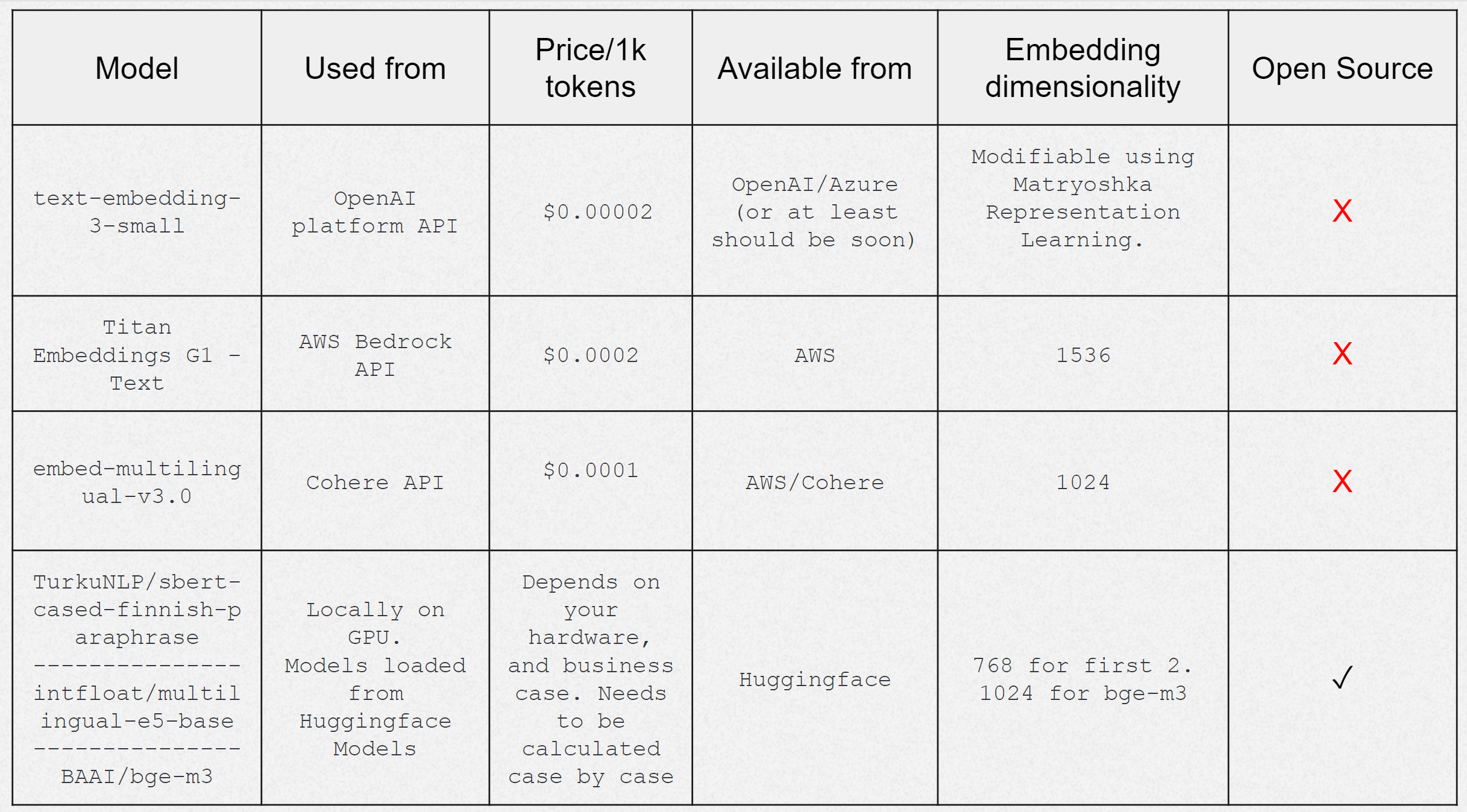
To ensure a comprehensive comparison, I gathered a diverse selection of embedding models, including open-source models from domestic and international players as well as cloud vendor models through APIs. Additional models may be included in this benchmark in future versions. The evaluated models included in the evaluation are listed in the table below.
Reranker models
Reranker models play an important role in refining search results or reordering output to enhance accuracy and relevancy. Their utilization aims to improve the performance of RAG applications, particularly in tasks where retrieving the most relevant information is crucial.
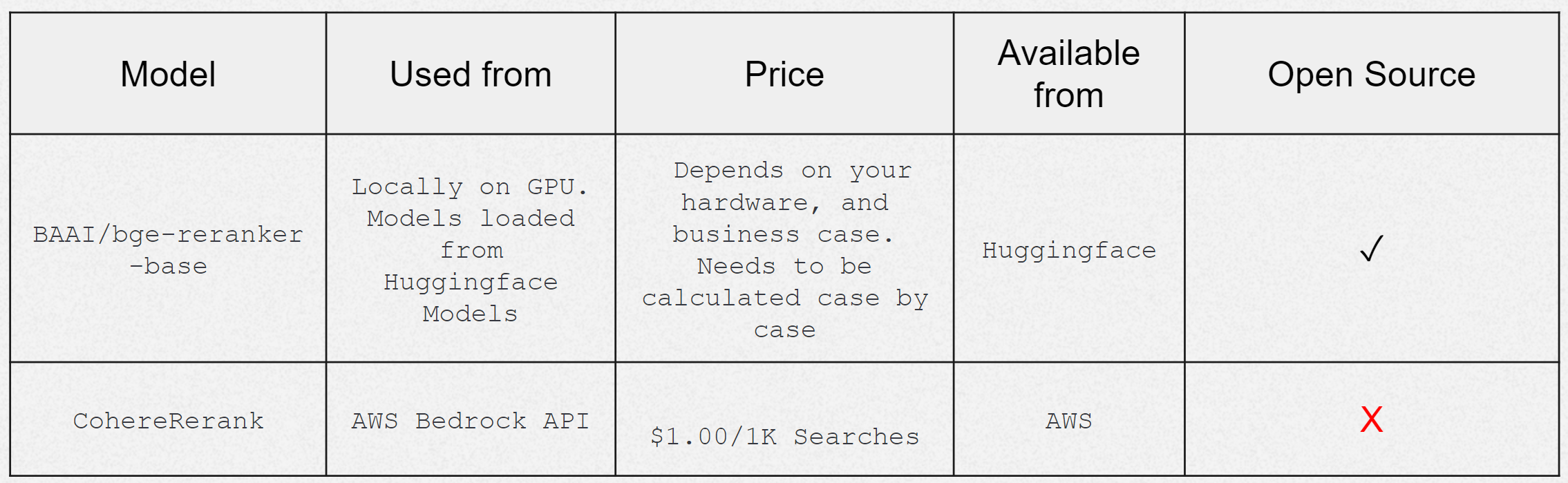
By adding these reranker models into the evaluation, I aimed to assess their effectiveness in improving the overall performance of the retrieval system for Finnish.
Evaluation process
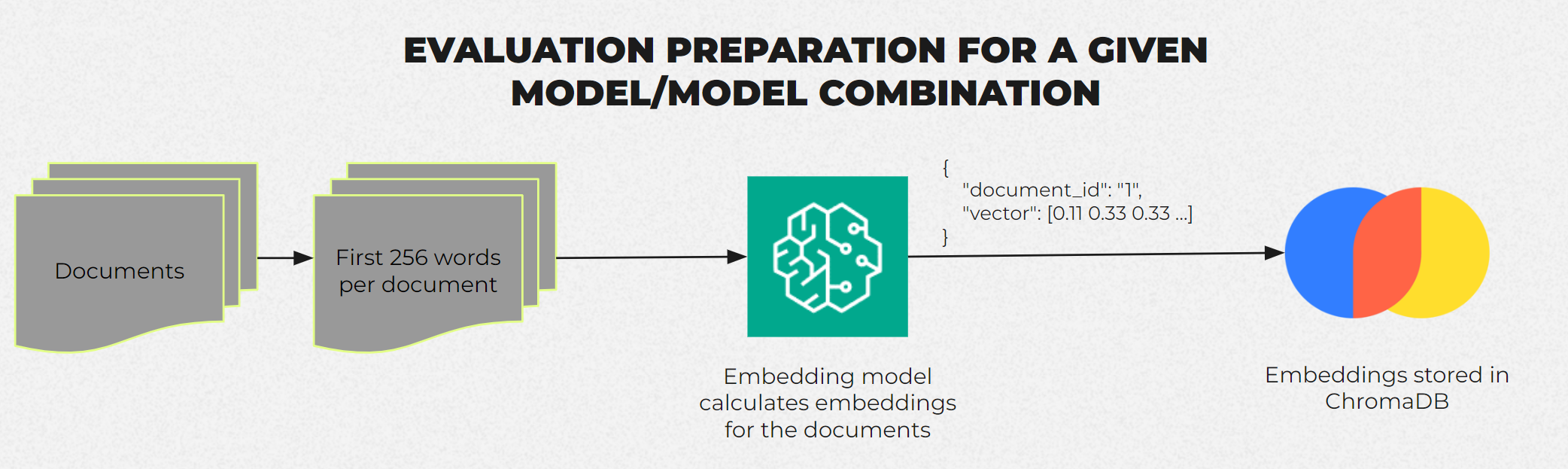
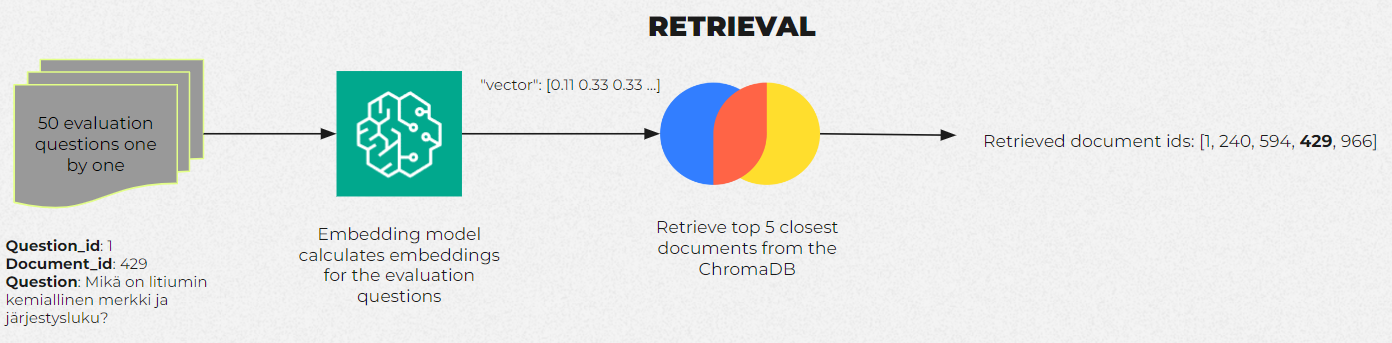
The evaluation process of the embedding models goes as follows:
-
Embedding data to ChromaDB:
First, we start by calculating the embeddings with the model we're evaluating to the ChromaDB. -
Query-Based Embedding and Document Retrieval:
The questions created in the evaluation data creation section are embedded using the current model under evaluation. Then, the calculated embeddings are used to retrieve documents from the embedded dataset that the evaluated model considers most relevant to the query. -
Reranking (if applicable): When using reranking models, we apply them to refine the document ordering with the reranker models. The main results in the evaluation section are calculated without reranker models as this seems to be the most common pattern currently in Finland. You can find the full results with the reranker models in the appendix section.
-
Metric Calculation: Once we have done the retrieval process for each evaluation question, we can finally calculate the hit rate and mean reciprocal rank (MRR) to measure the model's performance. More on this in the evaluation metrics section.
Evaluation metrics
When assessing the performance of embedding and reranking models, I decided to use hit rate and Mean Reciprocal Rank (MRR) as my main evaluation metrics. Hit rate in general gives an idea of how many relevant documents are retrieved among the top results. In this case, we are looking for one document. MRR is a measure of the average of the reciprocal ranks of the first relevant document retrieved. So, as we retrieve the top 5 documents in the testing, the value is 1/1 if our document is first on the retrieval list, 1/2 for second position, 1/3 and so on. And from these, we take the mean for 50 documents. These 2 are pretty good basic metrics for retrieval focusing on accuracy and relevance.
Additionally, I included time-based metrics such as embedding and retrieval duration to capture the computational efficiency of the models (or speed of the endpoints in the case of API models). These metrics offer valuable insights into the runtime performance of the models, which might be crucial for real-world deployment scenarios. I remain open to adding additional evaluation metrics in the next iterations of the benchmark to provide a more comprehensive assessment of model performance. Please let me know which metrics you would like to see in this benchmark in future iterations.
You can find the complete result tables containing all metrics, along with an additional video of me walking through the code, in the appendix section at the end of this blog.
EVALUATION RESULTS FOR EMBEDDING MODELS
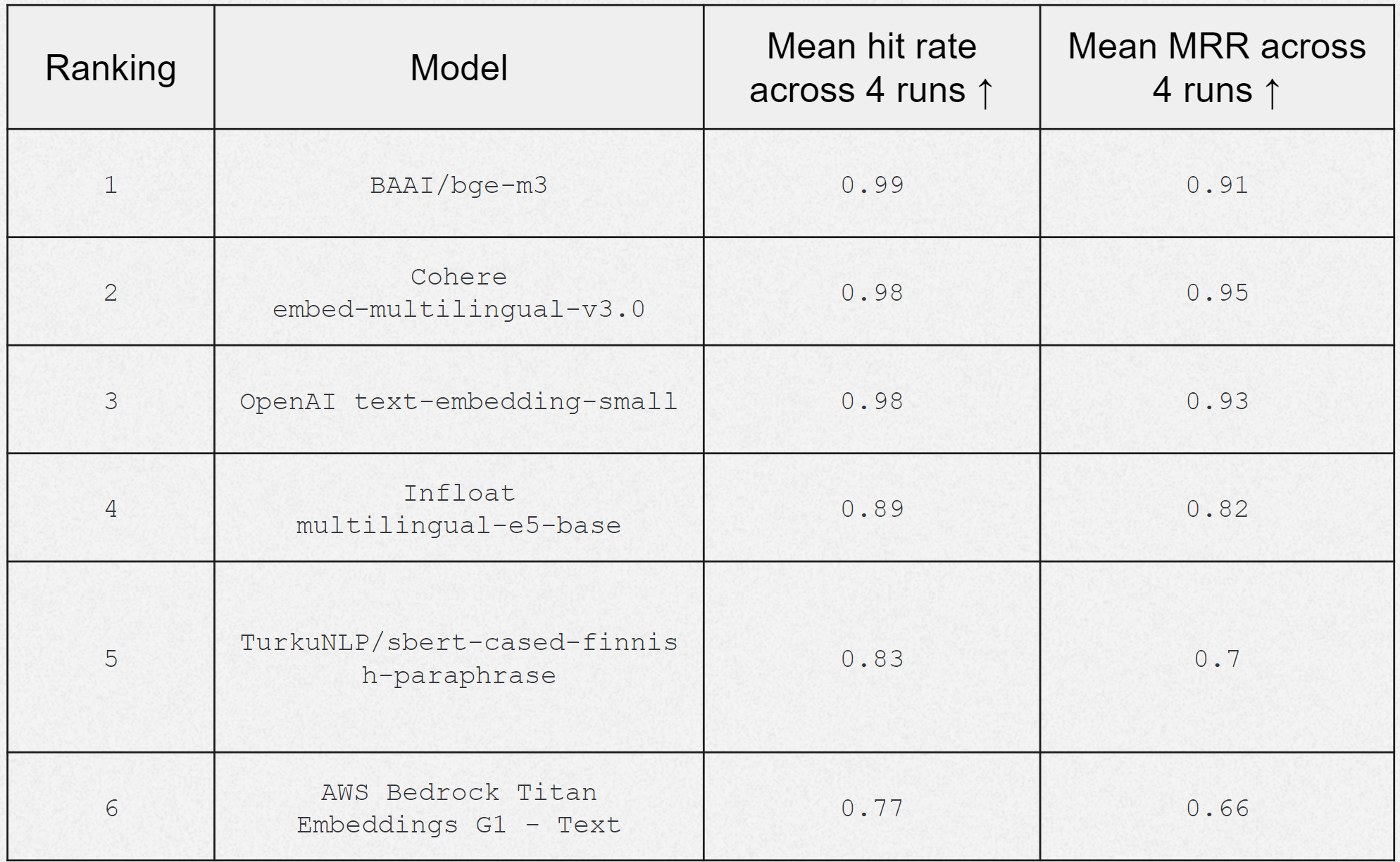
After looking into the results, there are a few things worth mentioning. The biggest thing to note is that the open source model came on top based on mean hit rating. This is in line with the findings of openai-vs-open-source-blog. When it comes to cloud vendors, one thing to note is how much better OpenAI and Cohere embeddings are compared to AWS Bedrock for Finnish language tasks. They consistently do better across different measures in all benchmark datasets in this evaluation, showing they're good at understanding the meaning and context of Finnish text. Also, the open-source models from infloat and TurkuNLP might, in some cases, be good choices, especially if you're willing to spend some time tweaking the models or mixing them with other methods like hybrid search.
It's good to see that there are other embedding models besides OpenAI that are competitive. It's not surprising to see Cohere's results, though, considering they have enthusiastic developers like Nils Reimers, who created sentence-transformers, a well-known open-source Python package for embedding models. But seeing open source at the same level in Finnish makes truly me very happy as an open source enthusiast.
These findings show how important it is to thoroughly evaluate and benchmark embedding and reranker models. By using evaluation frameworks and closely looking at how models perform across different datasets and tasks, businesses can make informed decisions to make their RAG solutions work better in real-life situations.
EVALUATION RESULTS FOR ReRANKER MODELS
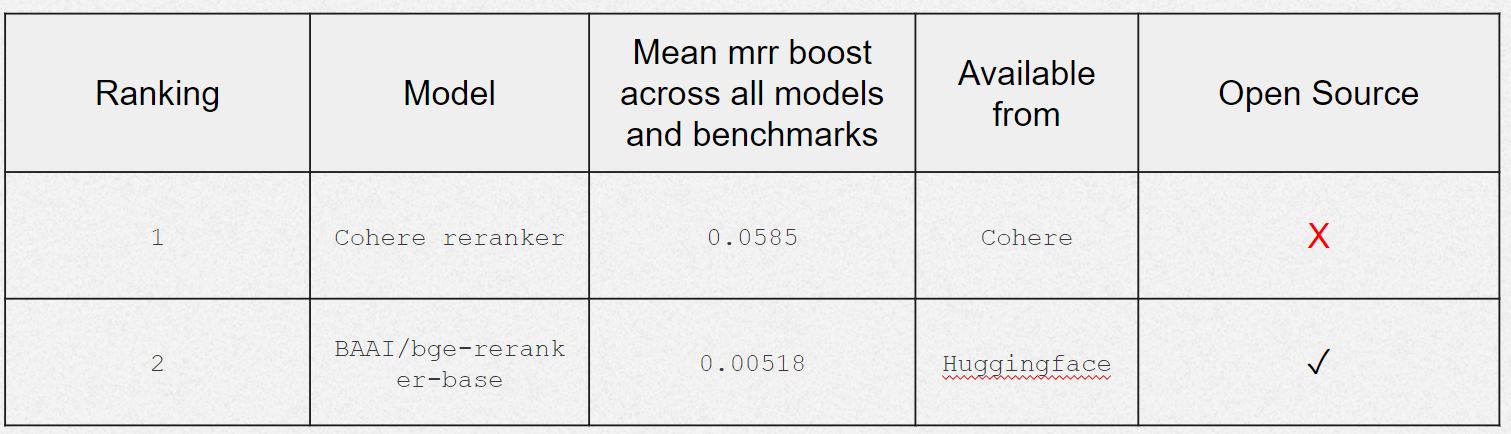
Reranker models hold promise for improving search outcomes and elevating Mean Reciprocal Rank (MRR) in Finnish retrieval tests. While this blog primarily focuses on embedding models, I also explored two reranker models, both of which yielded favorable results.
Cohere's reranker model exhibited slightly better performance, indicating its effectiveness in enhancing search precision and relevance. However, for this assessment, I chose to use only models.
In future iterations, I might expand this evaluation to include additional reranker models, such as BAAI/bge-reranker-large. For a deeper dive into the results, please refer to the appendix.
Conclusion
In conclusion, this evaluation of embedding and reranking models for Finnish language processing highlights the importance of rigorous benchmarking. As we can see, there are noticeable differences in how well the models work with Finnish. After reading this blog, I hope people don't just pick a cloud provider's embedding model without thinking about it first.
While this evaluation offers a useful starting point for comparing embedding and reranking models, it is not exhaustive. There are still other factors to take into account, such as splitting strategies, prompt expansion techniques, and advanced methods like HyDE which have the potential to further improve the systems performance.
Nevertheless, this evaluation lays a solid foundation for future research and experimentation. The code used in this evaluation is available in the Recordly Github, enabling somewhat easy replication and extension of the experiments. As such, this experiment and blog try to work as a starting point for businesses and researchers seeking to evaluate and optimize embedding and reranking models for RAG applications involving the Finnish language.
References
https://www.linkedin.com/posts/llamaindex_optimizing-embeddings-for-multilingual-rag-activity-7159951902045040641-thqV
https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83
https://towardsdatascience.com/openai-vs-open-source-multilingual-embedding-models-e5ccb7c90f05
Acknowledgments:
I wish to express my gratitude to Lauri Lehtovaara and Joonas Kivinen for their invaluable technical insights, and to Anni Mansikkaoja for her contributions to the visual and linguistic aspects. Additionally, I extend my thanks to Aapo Tanskanen from Thoughtworks for his feedback during the initial stages of drafting this blog post and its conceptualization.
APPENDIX
Experimental Setup
The experiments were conducted locally with a Jupyter Notebook in VsCode. For local embedding models, Nvidia RTX 4080 GPU with CUDA acceleration was used to enable efficient processing. The up-to-date code for the benchmarks can be found here https://huggingface.co/datasets/Recordly/Finnish-embedding-reranker-eval . If you want to see me running through the notebook take a look into this video below (Note that the code might have already changed a bit from this version. )
ME GOING THROUGH THE EVALUATION NOTEBOOK
Full results
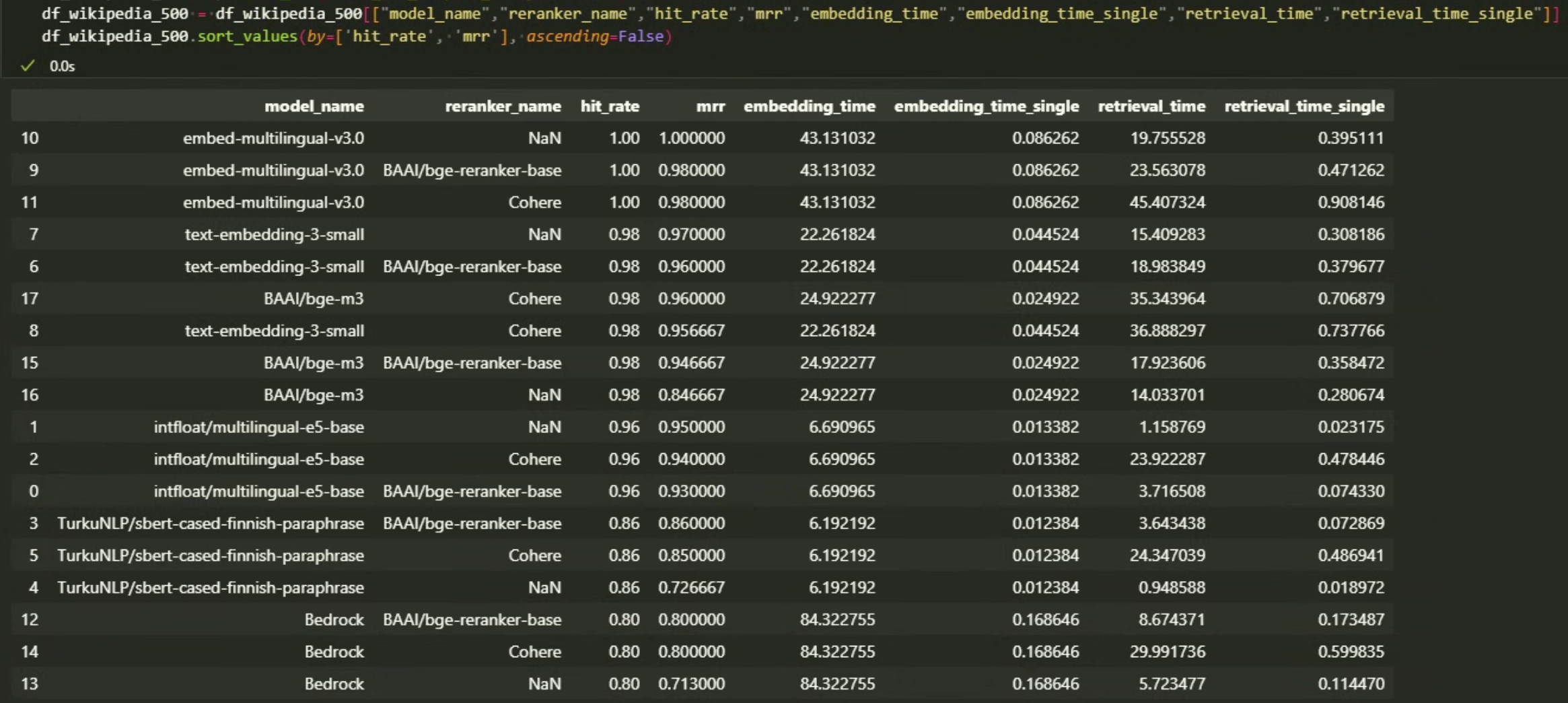
Disclaimer: For embedding and retrieval times the comparisons might be affected by the location of my PC and internet connection speed (250/50 Mbit/s). For OpenAI and Cohere embeddings I used their platform APIs. For AWS Bedrock titan embeddings I enabled the usage of the models in eu-central-1 region. I personally reside in southern Finland. Wikipedia, 500 articles, retrieve top_n = 5, rerank top_n=3, sorted by hit_rate, mrr
Wikipedia, 1000 articles, retrieve top_n = 5, rerank top_n=3, sorted by hit_rate, mrr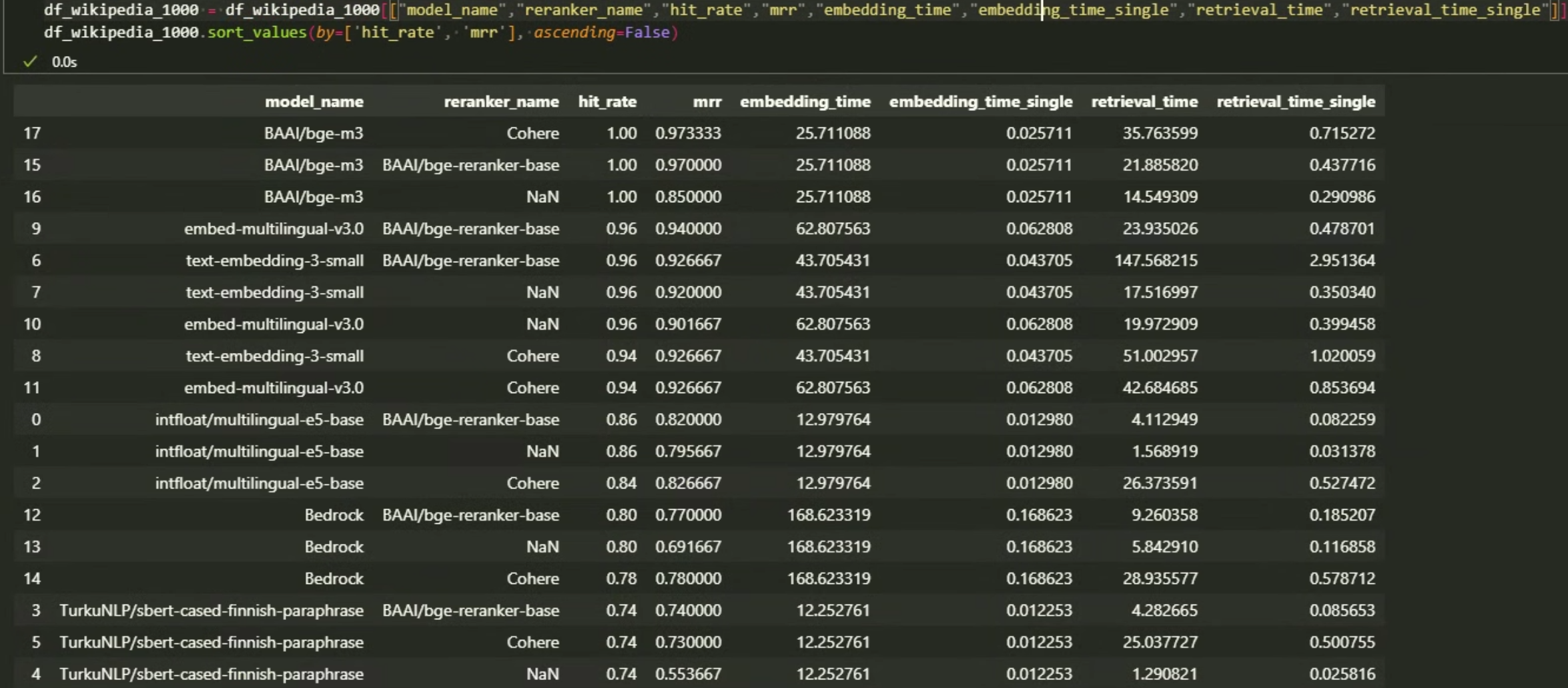
Journalist articles, 500 articles, retrieve top_n = 5, rerank top_n=3, sorted by hit_rate, mrr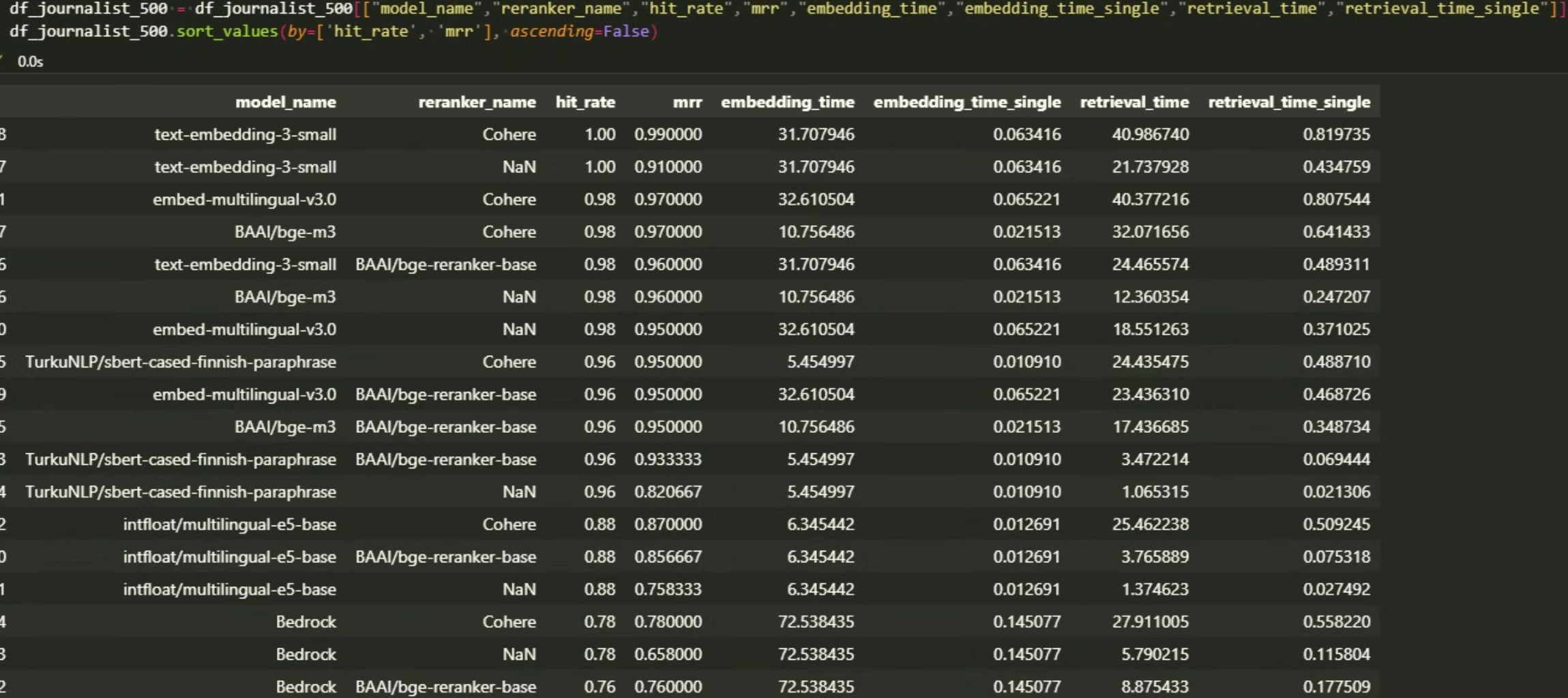
Journalist articles, 1000 articles, retrieve top_n = 5, rerank top_n=3, sorted by hit_rate, mrr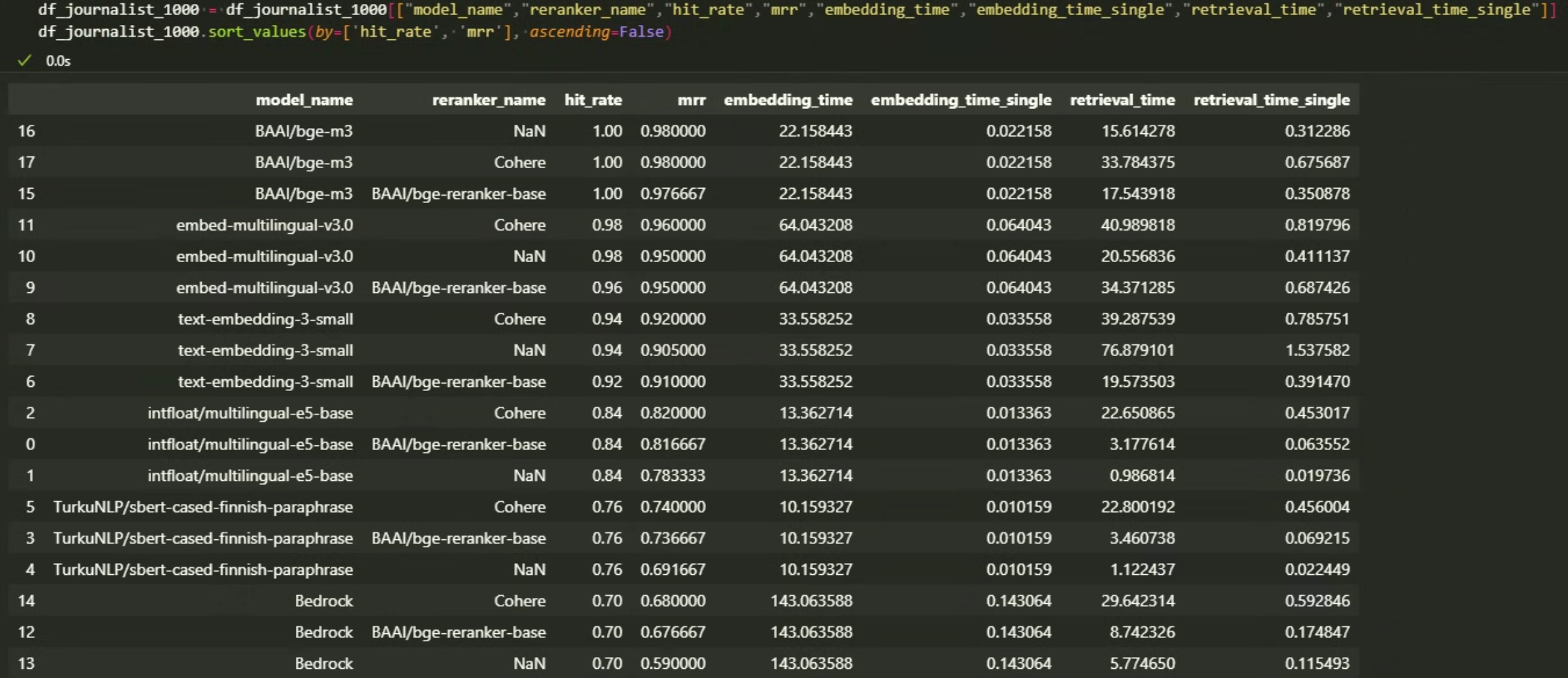
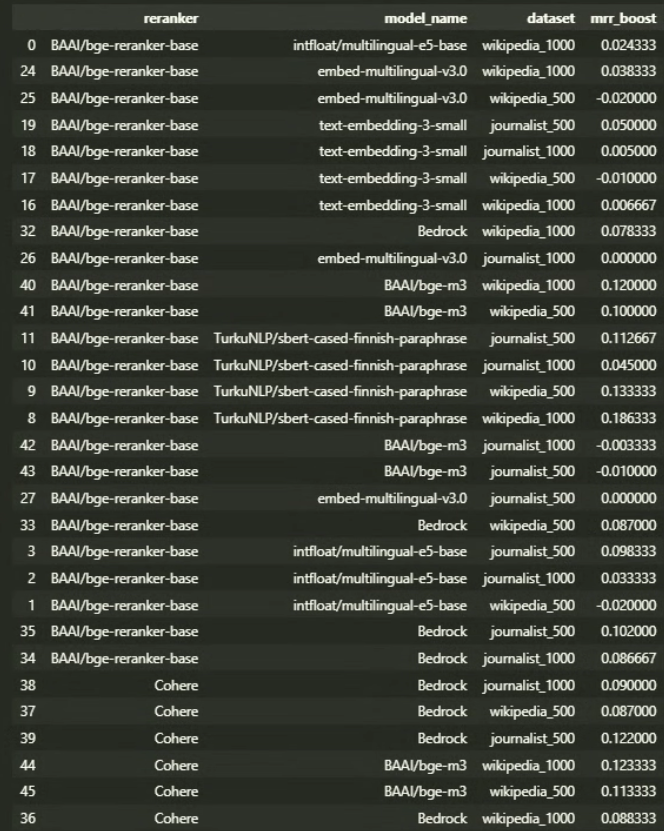
Reranker mrr boosts across all datasets per model/reranker combination
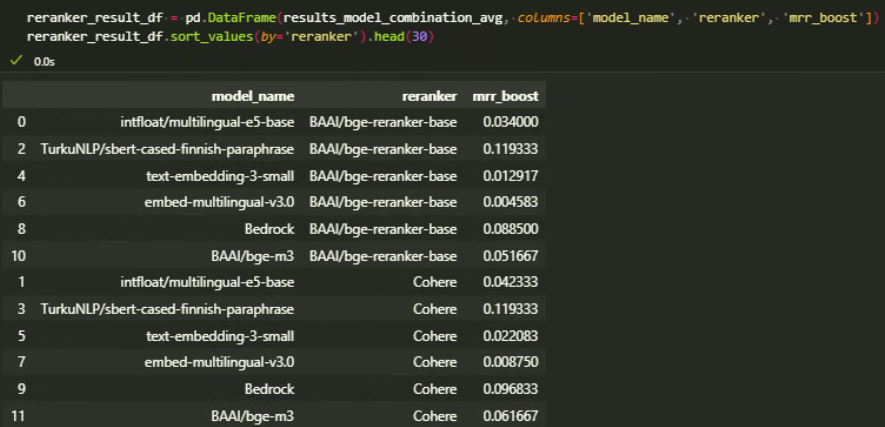
Detailed mrr boost results