Written by —

Written by —
For us at Recordly, the fact that technical data solutions should always serve the needs of the business and people is just as self-evident as the role of data in future success. In other words, it is about helping humans and data to cooperate so that the results are visible in daily life as well as the bottom line. Otherwise, technical data projects are just expensive exercises.
Last week, we brought together some like-minded data folk at the Accelerate Data with Snowflake & dbt -event in Helsinki. With the Lead Data Engineer at Neste, Afaq Latif, we dove into the practical side and impact of business-driven data work at the Finnish conglomerate.
We also had the chance to hear a bit more about the components that play a vital part in the data projects at Neste: Snowflake and dbt. At first, Country Manager Markus Päivinen from Snowflake presented their journey to Data Cloud and showcased some of their plans for the future while our very own Data Architect Mikko Sulonen shed light on the dbt’s side of things.

It was not the first time Mikko shared his dbt expertise. Since 2019 and the 0.14 version of dbt (it was apparently the time when dbt snapshots were introduced as “snapshots” and not “archive” anymore…), Mikko has been playing around with it. Last October, Mikko also participated in the dbt Coalence in New Orleans. He shared some of the highlights from the event after his trip.
Starting with a quick backstory to dbt and following up with the direction forward into the future, we’re happy to share some highlights again only this time from Mikko’s own presentation at the event last week.
HOW DID THEY GET HERE?
As a quick reference for those of us who may need it – especially fellow business people who may sometimes feel overwhelmed by the technical side of things – dbt is “a data transformation tool that enables data analysts and engineers to transform, test and document data in the cloud data warehouse”. Capiche? No need to worry if not fully, the following should help with that. You see, there are two main reasons for dbt’s existence.
In general, engineers and analysts have different tools to answer the same question. On one hand, we have data engineers who work with a data warehouse. This includes stored procedures, SQL, SSIS, Informatica, ADF, etc. On the other, we have analysts working on BI tools such as Power BI, Qlik Sense, Ad Hoc DW queries, and custom transformations.
The letters may not say anything to some of us but the key thing to remember here is that both of these groups are essentially answering the same questions with their own set of tools. It does not take a data engineer to understand that this is not maybe the smarties, quickest, or most efficient approach. In practice, it is deepening analytic debt and lengthening the time to insight. Another result is a fragile network of tables that are untested, error-prone, and difficult to unwind. Downstream tooling is also rendered unusable, wasting resources and jeopardizing business outcomes
The folks at RJ Metrics, later Fishtown Analytics, and now dbt Labs, started to wonder, that there has to be a better way. They started to gather best practices from their projects, put them together, and ended up with a data-build tool.
To understand the other reason why we nowadays have dbt around, let's take a look at a specific picture that Mikko showed last week:
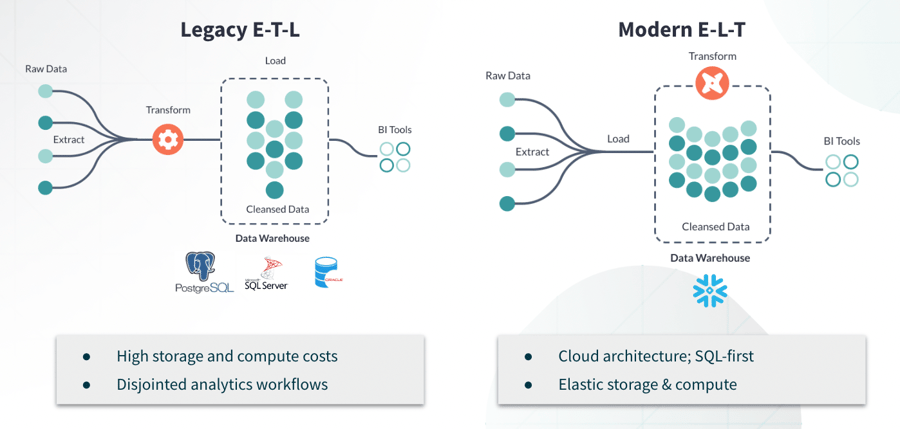
As we can see, data transformation can and used to be a lengthy and resource-intense process. Storage and computing for legacy databases like Postgres and SQL Server were also expensive meaning that most transformations had to take place outside the warehouse.
Cloud warehousing has made storage and compute cheaper, which has allowed transformation to happen in place. Cloud warehousing is also SQL first. This leads to more possibilities with merely SQL combined with elastic cloud compute.
BACK TO THE NOW
Tackling the issues mentioned above, dbt came to be as we know it today. It provides a framework to develop transformations, test, and document changes, and deploy products with confidence. In practice, dbt sits on top of one’s data platform (such as Snowflake or Databricks) and integrates with two main things: Git provider and data warehouse.
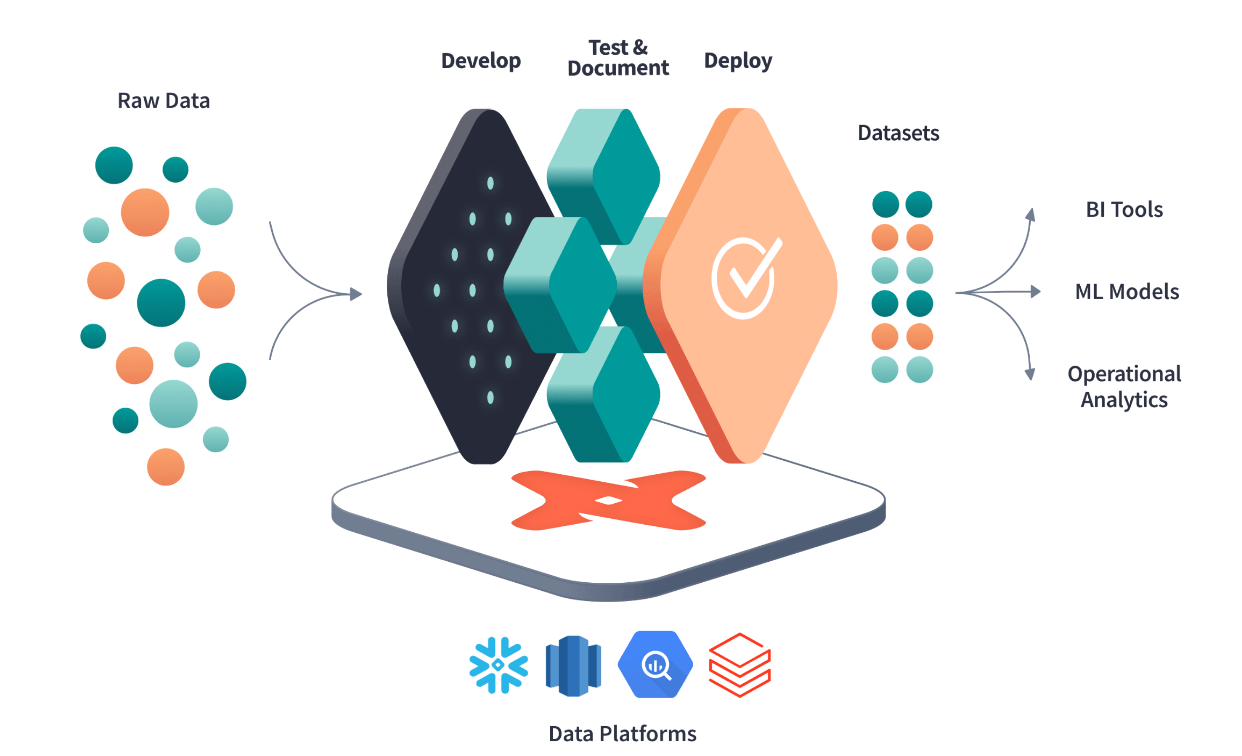
To simplify this all, dbt gives Data Engineers and Analysts the same tooling, documentation, and language to produce and use data products. In a way, dbt’s vision was to combine these two roles into one, an Analytics Engineer.
Another way to look at dbt’s viewpoint is building data like developers build applications. dbt unites SQL and Python, the two major languages in data development. While SQL is used by every cloud data warehouse and most data teams, Python is used by the majority of data scientists and is known by everyone in the data domain. Bringing these two languages together means more people share the load, and do the transformations.
But it’s not just about who is transforming data – it’s how. This is where engineering practices take the stage. Rigorous testing, version control, continuous integration, and automated documentation – all things that should ring a bell with anyone who works in tech despite their role – improve quality, but also just enable better governance. Software engineers have been working like this for years. dbt has just made these principles applicable to data.
In many organizations, it's common for one person to wear multiple hats or have distinct roles with skill overlap. So while your typical SQL users are usually thought of as Data Engineers, Analytics Engineers, or Analysts, and tour typical Python users are usually thought of as Data Scientists or Machine Learning Engineers, there is a lot of language overlap already between these roles in reality. That’s probably most apparent for Data Engineers, but you definitely have Data Scientists and ML Engineers who are using SQL and Analytics Engineers and Analysts using Python. The main point is that these languages are not mutually exclusive and dbt wants data practitioners to be able to switch fluidly between languages to solve their problems.
So instead, let’s bring these teams together: Bringing Data Scientists closer to Data Engineers, and Data Engineers closer to Data Scientists. This helps bring down the silos. This enables better collaboration which should make sense to even the least tech-savvy decision-makers in the business side of things who are still hopefully reading.
WHY PYTHON?
Many data practitioners consider Python to be their first and most prominent language for working with data. By providing them with the dbt framework – that so many SQL users already benefit from – their daily lives get simply better.
The next point is that dbt is sitting on top of data platforms that support Python. Bringing Python into dbt is a natural step to ensure the utilization of the capabilities that these data platforms provide while still utilizing the dbt framework. An extension of that is that the user is now able to deploy Python and SQL code from within dbt.
The big question that all of this brings up to the users is what they use Python and what SQL for. Makes sense. This is a part of the unknown where there’s no strong, opinionated set of Python best practices yet. However, in one situation there’s a clear advantage to using Python:
Python:
df.[“mvg_avg”]=df.trips.rolling(14).mean()
SQL:
avg(trips) over (order by date rows between 13 preceding
and current row) as mvg_avg
This is an example of a 14-day moving average, where instead of using a window function that is definitely complex from a SQL standpoint, you have a concise and easy-to-read Python transformation accomplishing the same thing. You can find more examples here.
ALRIGHT, SO WHAT?
According to Mikko and the folks at dbt, Python shines in data munging and processing, particularly where there’s a package that you can easily pull into a model that would otherwise take a long time to build out in SQL. From the data science standpoint, there’s apparently a lot of cool advanced statistical, forecasting, and predictive work that can be done.
HOW DOES THIS WORK IN PRACTICE?
Now that we're all on the same page concerning dbt and why it exists, it's time to explore the possibilities in your context. Hit us up to book a free slot for a 2-hour workshop with us at Recordly. The workshops are free of charge and available for booking only until April 30th. However, there's only a limited number of slots so book yours as soon as possible by clicking below.




