Written by —
Written by —
Coalesce 2023, The Analytics Engineering Conference crafted by dbt Labs, happened last week in San Diego, California 🌴. Here's a short recap of the major announcements from Coalesce.
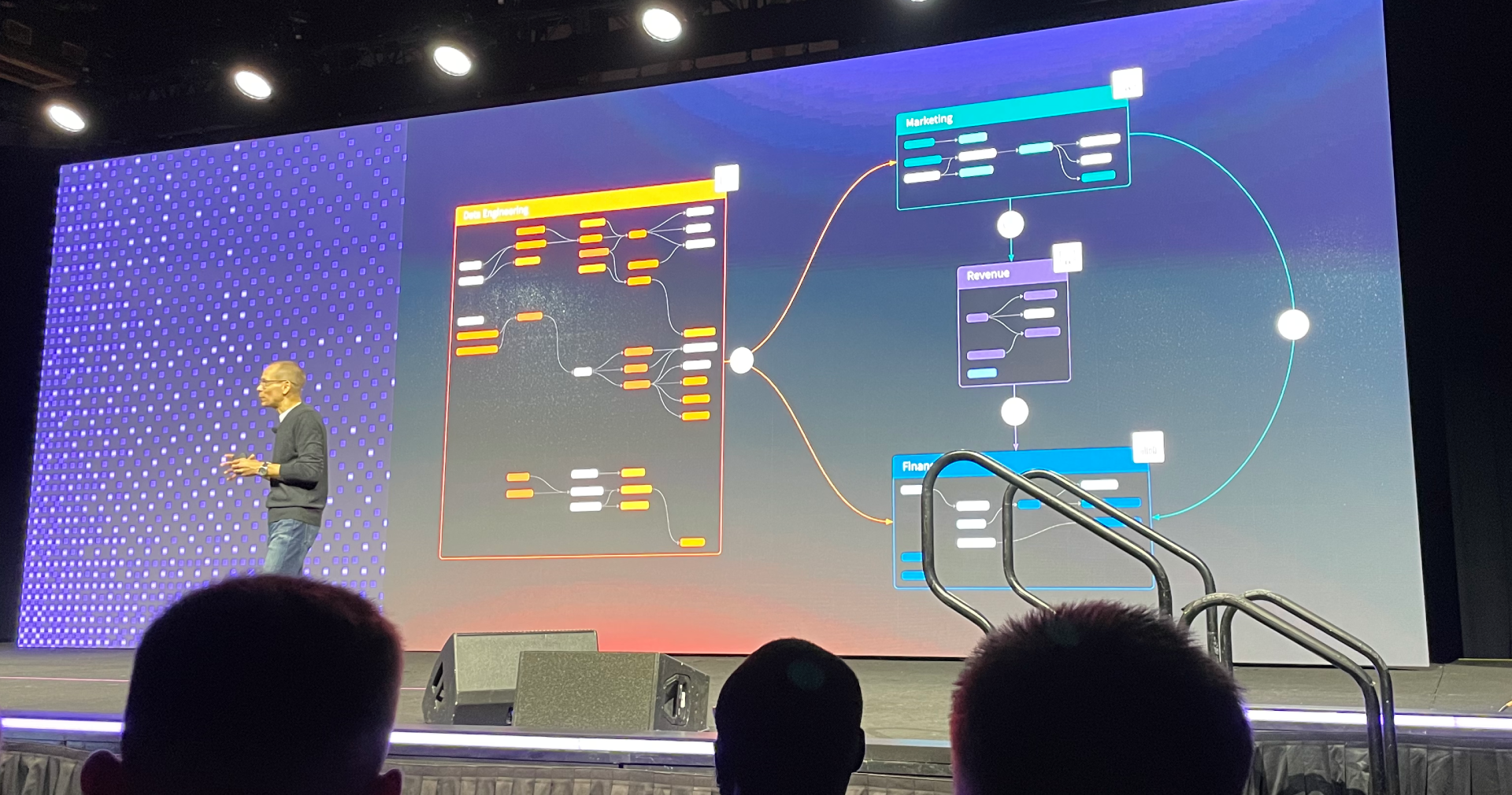
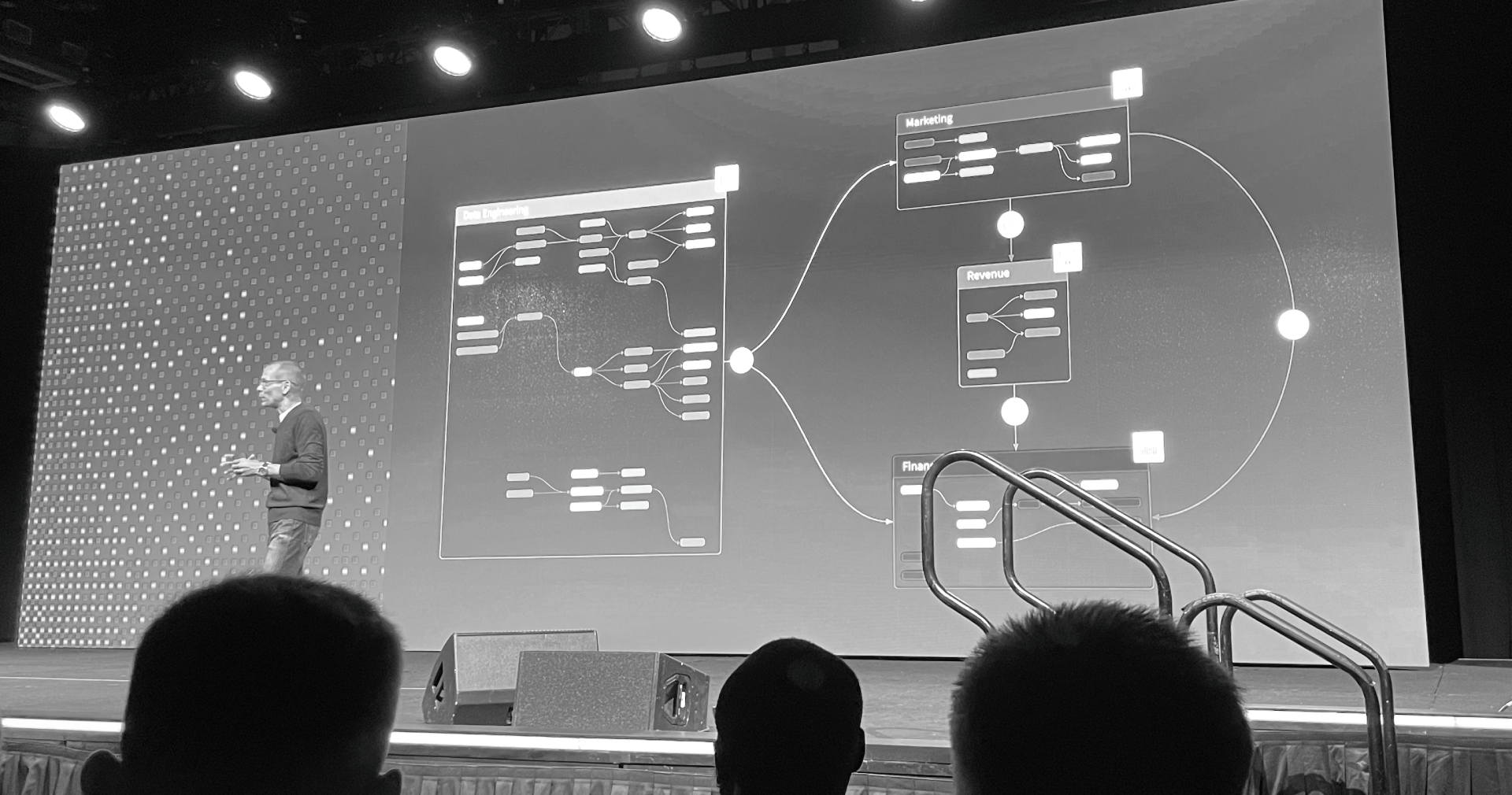
dbt Mesh from keynote
dbt Mesh
dbt Mesh is not just one new feature: it's a bundle of features aimed at enabling development at scale. Jeremy Cohen from dbt Labs shared some examples of the enabled scale: customers with 500 projects, most substantial projects having 100+ active developers 📈
dbt Mesh is built from cross-project ref, dbt Explorer, model versions and contracts, and access levels and groups:
- Cross-project ref
- Adding a dbt project dependency and using a two-part ref-syntax. And that's it! Using a model from a different project is as simple as that. At the moment, you are constantly referencing the production version of the referenced table. Some additional changes might be coming up. Think of referencing a parent test environment in the child project dev/test environments.
- dbt Explorer
- A complete overhaul of the dbt Docs in dbt Cloud. Built on a new Discovery API, it's an always up-to-date presentation of all of your projects at that very moment. Improved lineage, going across projects, dbt-test statuses, suggestions based on dbt Labs best practices, and more. A big usability update for just single projects as well!
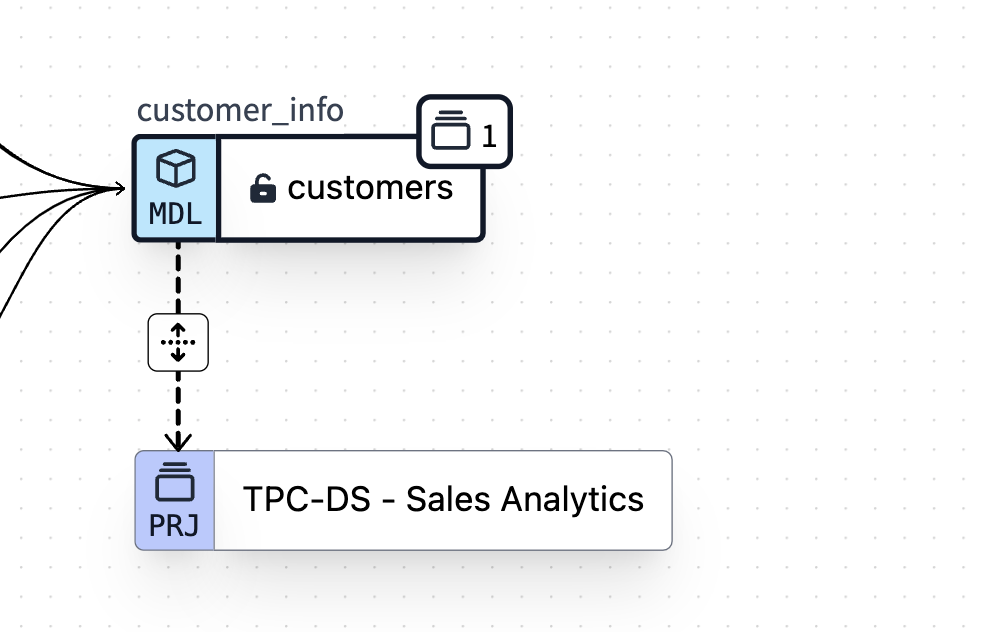
dbt Explorer: A child project TCP-DS - Sales Analytics, is referencing a parent project model customers - Model versions and contracts
- Keeping your published data products and developers updating those in check and having a straightforward process and tools for introducing breaking changes to published products. The short story is: contracts stop you from making breaking changes to a contract-enforced model. Versions are then the tool and process to introduce those breaking changes to your models: changing a column data type and removing a published column. You can also introduce deprecation dates, notify your data product users about upcoming deprecation, and have them react to forthcoming changes.
- Access levels and groups
- Publishing only the models meant to be published, and not sharing your intermediate steps. At the moment, there are three access levels:
- Private: access from the same group
- Protected: access from the same project. The default.
- Public: access from any group, package, or project
- Publishing only the models meant to be published, and not sharing your intermediate steps. At the moment, there are three access levels:
The access levels and model groups are for more than a multi-project or dbt Cloud environment. In a large dbt project, it might be helpful to create domain-specific model groups to limit the intermediate model usage: dbt will refuse to "ref" a model even in the same project when you've set them to private. Groups can bring clarity to just one project this way.
dbt-meshify
With the introduction of dbt Mesh, there's an obvious requirement for moving many monolithic dbt projects to multi-projects. To help with the transition, dbt Labs has created dbt-meshify! An open-source CLI tool to help create groups, versions, and child projects. It completely automates the creation of yaml-files, dependency creations, versions, and two-part refs.
And it's not just for cross-projects. If you plan to introduce refs or groups on your single-project dbt Core project, you should check it out. dbt-labs/dbt-meshify in Github
Re-launch of the semantic layer
dbt Semantic layer was re-launched, now powered by MetricFlow. It is an understatement to call this a re-launch: the previous version looks like the alpha or the beta version compared to the current one.
The basic gist is that you define the components and how they are related. Then, you query the Semantic Layer from your BI tool or via GraphQL or JDBC. The architecture and the idea are the same as the previous year:
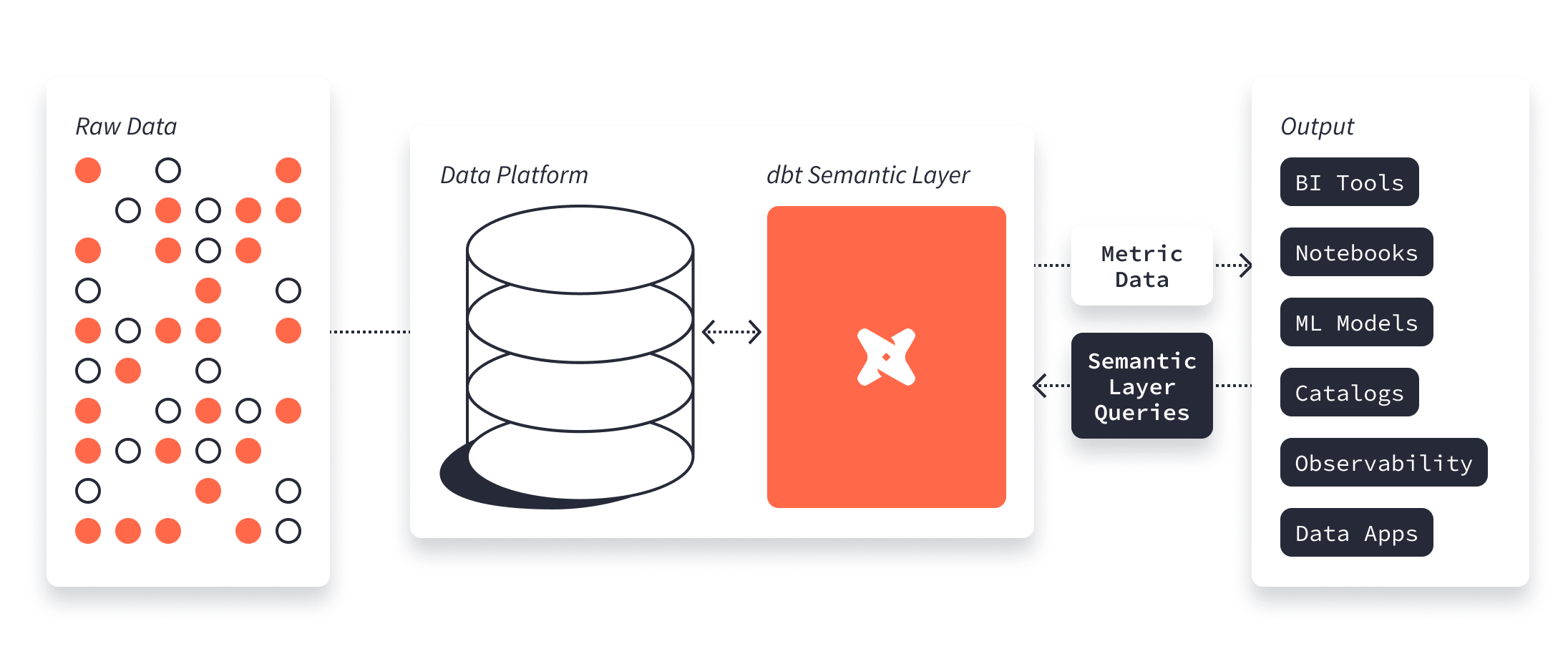
The components are:
- Semantic Models
- Your dbt defined models, published on Semantic Layer
- Entities
- Usually, your key-columns
- Measures
- The more simple aggregations: sums, counts, averages
- Dimensions
- Point of Views for Measures. Think: "Measure by Dimension"
- Metrics
- Complex Measures. If a measure is "Revenue", a Metric is "Rolling 12-month Revenue."
- Or a Metric based on another Metric: "Gross Revenue" = "Profits" - "Costs"
The architecture stays the same: The dbt Cloud semantic layer sits on top of your DW (now supporting Snowflake, BigQuery, and Databricks, by the way!) and takes the queries from downstream users. It then translates them on the fly to the target DW SQL and sends the queries to the DW. Results are returned to the end user as soon as they are available.
We are already seeing some exciting implementations here. Since the Semantic Layer has the definitions of your business models, entities, metrics, measures, how to join all of these, and how to form the proper SQL, it's an excellent pairing with Large Language Models. Zenlytics is already providing an LLM chatbot that integrates with a Semantic Layer, and with the Semantic Layer definitions, it should always return correct results and not hallucinate on its own.
dbt Cloud CLI
Now you think that with the cross-project ref, a dbt Cloud only feature, how will you work with both dbt Core from your VS Code or another editor and with dbt Cloud? There's now the dbt Cloud CLI. It aims to be a drop-in replacement for dbt Core and behaves the same way as dbt Core. The only differences are that all the execution gets pushed to the dbt Cloud and that the cross-project refs are evaluated from the dbt Cloud Discovery API.
It streamlines the installation workflow for a local dbt setup in a dbt Cloud project. Do note that it installs as "dbt" on your CLI so that you will clash with your current installation of the dbt-core adapter. And since the profiles.yml is replaced with dbt Cloud references, some extensions need to be fixed now.
And something for dbt Core
This year, many announcements focused on dbt Cloud and are paid product features. However, dbt Core being open-source and at the heart of dbt Cloud as well, there's also something exciting for dbt Core users.
In the 1.6 betas, a Python API was introduced to dbt Core. There's an open-source package called dbt-loom, which provides similar cross-project referencing to dbt Core! Beware that the Python API is currently documented as unstable, and the functionalities are subject to change. Nevertheless, it's a great example of what the community can build when the core is open-source! nicholasyager/dbt-loom in Github
Not sure where to start with dbt?
Would dbt be a good fit in your data stack? How does it compare to your current setup or what you have in your plans right now? We can set you up with a data tools comparison, or run an extensive dbt workshop to jump-start your development with best practices in your environment.
Viva Las Vegas?

Now, after two in-person Coalesces, it's a well-established tradition to publish the location of the next Coalesce at the closing keynote. So for 2024, dbt Coalesce is going to Las Vegas! The process of attending conferences is quite straightforward with us (check last year's blog post for reference at Coalesce 2022), so if you like working with dbt and we see it as an excellent investment to attend again, I'd be more than happy to have a coworker with me in the casino floors!



